 lane4dev
lane4dev
从 LLM 到 Agent
大语言模型(LLM)本身就像一个见多识广的咨询顾问:能聊天、能解释概念、能写代码。可一旦深入使用,你很快会发现几个明显的短板:
- 做复杂数学运算容易出错
- 推理链条一长就开始“胡编”
- 碰到知识更新很快的领域(比如医疗、金融政策)就不太可靠
LLM Agent(智能体),就是为了解决这些问题而生的一种应用形态: 它不再是“问一句、答一句”的模型调用,而是让 LLM 担任大脑,再配上规划、记忆和工具,去执行一整套复杂任务。
LLM Agent 的基本框架
可以先用一张总览图,把 Agent 的几个核心部分放在一块儿看。
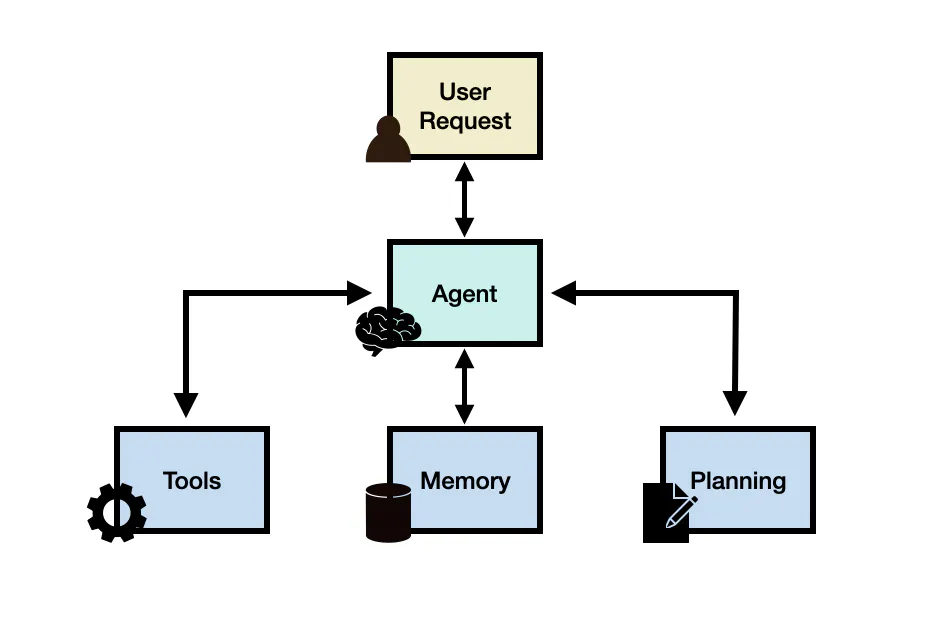
一个典型的 LLM Agent 框架,通常包含四个关键角色:
-
用户请求(Prompt) 用户抛出一个问题或任务,比如:帮我评估这个健康报告是否有异常,并给出建议。
-
智能体核心(LLM 大脑) 由大语言模型担任,负责理解任务、做推理、决定下一步要干什么。 它不再只是直接回答,而是会规划步骤、调用工具、读写记忆。
-
规划模块(Planning) 把大任务拆解成一系列可以落地的子任务:
- 先查什么?
- 再调用哪个 API?
- 中间需要记录、对比哪些结果? 这一步直接影响智能体是不是“看起来很聪明,做事却瞎忙”。
-
记忆模块(Memory) 用来保存智能体的经历和上下文:
- 当前对话中已经做过什么
- 之前和用户的互动
- 历史任务中总结出来的经验
-
工具(Tools) Agent 与外界的桥梁, 比如:搜索引擎、数据库、知识库、代码解释器、数学引擎、业务 API、第三方服务等等。
为什么单纯的 LLM 不够用?
当 LLM 单独工作时,会遇到几个典型难点:
-
数学运算不可靠: 大模型本质上是“预测下一个 token”,而不是算数器,所以大数乘法、金融计算很难保证每次都对。
-
复杂推理容易崩: 推理链太长时,很容易出现逻辑跳跃、前后矛盾、步骤漏掉。
-
知识有时效: 模型的知识固化在训练数据里,对训练之后发生的事情不掌握。
于是,Agent 的思路就是: 把 LLM 从一个会说话的大脑,变成一个会用工具、会反思、会改计划的执行者。
这背后有几个关键能力:
- 通过函数调用 / 工具调用,把任务交给外部系统处理
- 根据反馈审查自己的中间结果
- 如果发现走偏了,能重新调整计划
规划
无反馈规划:一次性计划好
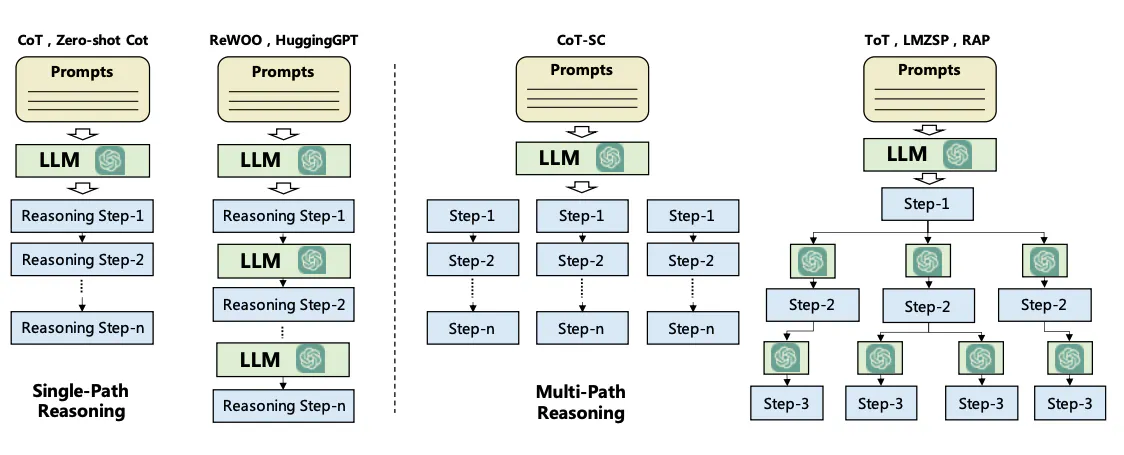
在无反馈规划的模式下,规划模块会把用户请求拆分成一串步骤,Agent 再顺着这条路线一路执行。这里常用两种思路:
-
思路链(Chain of Thought, CoT) 一条直线式推理路径,从头推到尾,适合结构相对清晰的问题。
-
思路树(Tree of Thoughts, ToT) 多路径推理,像在不同方案之间“分叉—探索—回溯”,更适合复杂问题的方案搜索。
典型流程是:
- LLM 根据用户请求,生成一份详尽的“任务清单”
- Agent 按步骤依次执行:查数据 → 调用工具 → 汇总结果
- 最后把整理好的答案反馈给用户
这个模式的优点是简单直接,缺点是一旦最初的规划有偏差,中途就不太好修。
有反馈规划
现实任务往往不会一条路走到底,尤其是跨多个系统、需要试错的场景。 这时就需要有反馈的规划:
根据以往的行动和观察结果,不断反思、调整计划。
比较有代表性的两类方法:
- ReAct:把“思考(Thought)”和“行动(Action)”交替进行
- Reflexion:在任务过程中不断做“自我复盘”,用过去的错误指导后续行为
以 ReAct 为例,它的运行节奏大致是:

- Thought:LLM 先在脑子里想一步:“我现在应该做什么?”
- Action:决定调用某个工具(比如搜索 API、数据库查询、数学引擎等)
- Observation:读取工具返回的结果
- 回到 Thought:结合最新信息,决定下一步流程
- 重复若干轮,直到任务完成或达到终止条件
这种机制的核心价值是:
让智能体有犯错—修正—变聪明的空间,而不是一次规划决定全部。
记忆
一个真正有用的 Agent,不能只活在当前这几条消息里,它需要某种形式的“记忆”。
大致可以分成两层:
短期记忆(Short-Term Memory)
- 主要用于保留当前任务 / 当前对话的上下文信息;
- 通常直接依赖 LLM 的上下文窗口(prompt 中带上历史消息和中间结果);
- 有时间和长度限制:上下文太长就塞不下了。
长期记忆(Long-Term Memory)
- 记录智能体过往的思考、行动、观察结果,以及用户的长期偏好;
- 需要存储在外部系统中,如向量数据库、文档库、日志系统;
- Agent 在需要时,通过检索相关内容,再把结果喂回 LLM。
简单理解:
短期记忆:我们刚刚聊过什么?
长期记忆:我们之前一起做过哪些项目、踩过什么坑、总结过哪些经验?
工具
Agent 之所以比普通 LLM 更像一个能干活的同事,关键在于它会用工具。
常见的工具类型包括:
-
信息检索:
搜索引擎(如调用 Wikipedia API)
内部文档检索(RAG 系统、向量库)
-
计算类工具:
数学引擎、符号计算系统
代码解释器(执行 Python、SQL 等)
-
数据系统:
业务数据库
数据仓库 / OLAP 系统
领域知识库
-
外部服务 API:
支付、物流、健康数据、财务报表系统……
LLM 的职责是决定工具怎么用、什么时候用,工具负责干实事。
lamaIndex 的 DataAgent:一个具体例子
上面说的是抽象概念,下面用一个具体框架来落地下:LlamaIndex 的 DataAgent。
DataAgent 是什么?
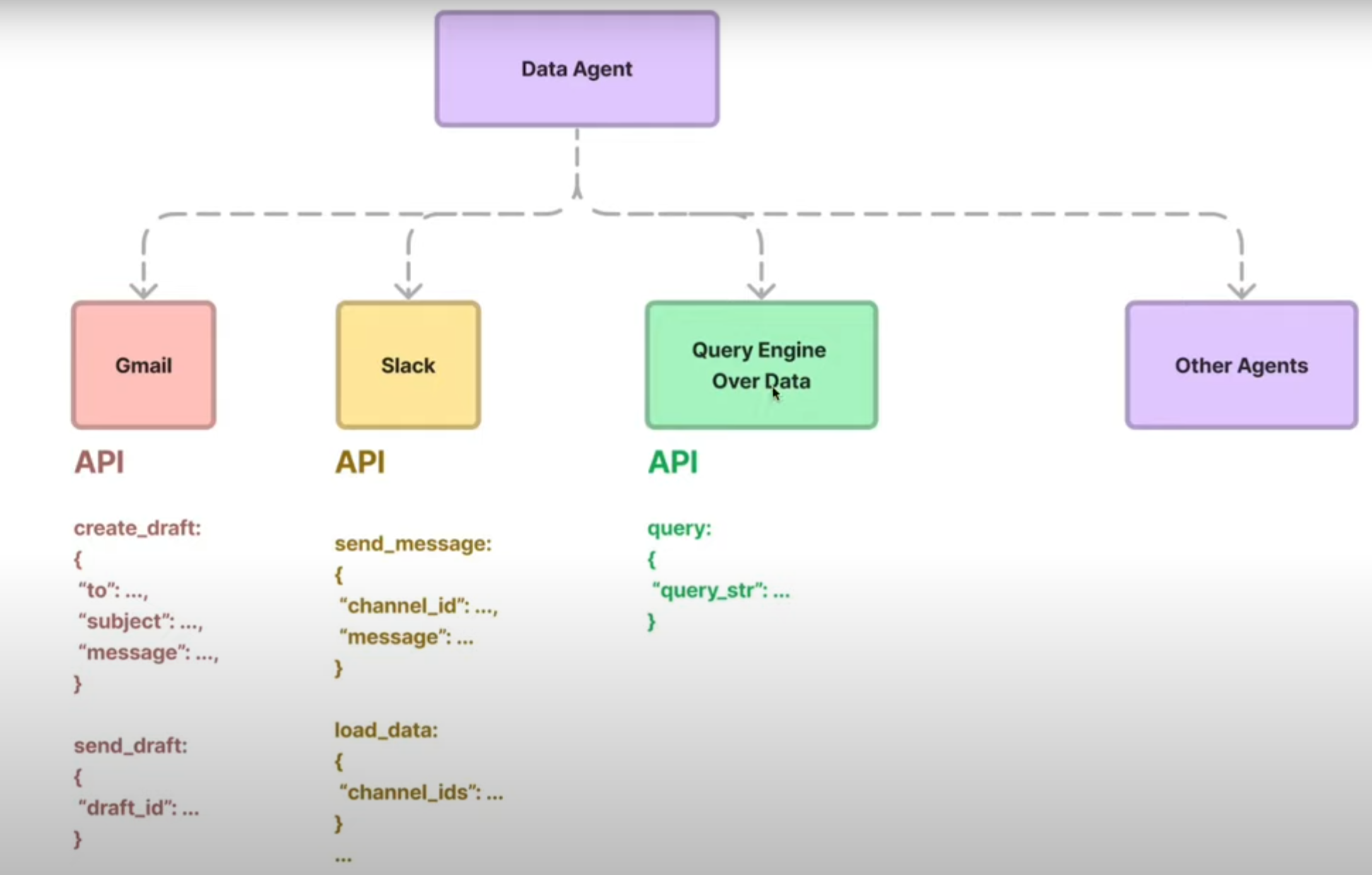
LlamaIndex 中的 DataAgent,可以理解为专门面向 各种数据源 的 Agent:
- 能接收自然语言请求;
- 能自主选择合适的数据工具;
- 既能读数据(检索/查询),也能写数据(通过 API 修改、保存)。
相比传统的“查询引擎”,DataAgent 更像是一个会自己行动的数据助手:
- 支持非结构化、半结构化和结构化数据;
- 可以动态摄取新数据、调整策略;
- 可以根据任务需要,组合多个数据源和工具。
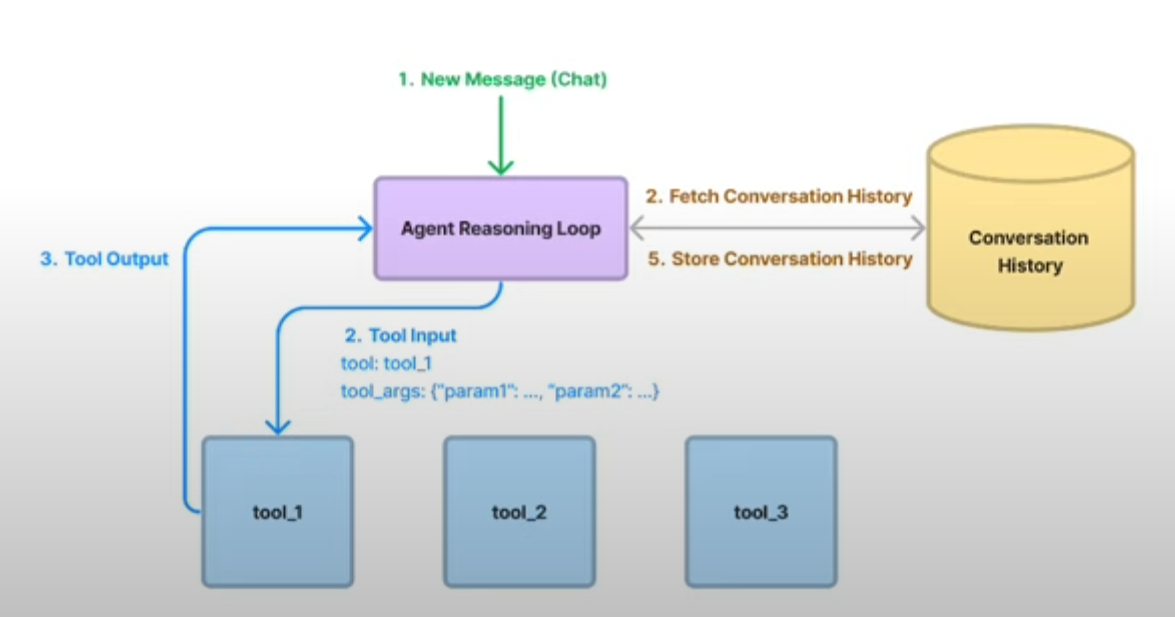
推理循环
在 LlamaIndex 的设计里,DataAgent 的核心是一个推理循环(Reasoning Loop):
-
每一轮循环中,Agent 会:
- 根据当前目标和上下文思考下一步要做什么;
- 选用合适的工具(查询引擎、函数调用、外部接口…);
- 获取结果并更新自己的判断;
- 决定是继续分步执行,还是可以返回最终答案。
在实现上,LlamaIndex 提供了多种 Agent 形态,比如:
- ReAct Agent:基于 ReAct 策略,一边思考一边行动;
- FunctionCallingAgent:聚焦在“函数调用”这个统一抽象上,可以对接不同 LLM 或外部工具;
- LLMCompiler Agent 等实验性形态(更复杂的任务编排)。
工具抽象
在 LlamaIndex 里,Data Agent 不是一个单独的类名,而是一种Agent + Tools + 推理循环的模式。
代码层面上,它通常是通过 FunctionAgent(基于 OpenAI function calling)
或者 ReActAgent(基于 ReAct 策略)来实现的,再把各种数据访问能力封装成 Tool 塞给它。
下面这个例子,用的是最简单的 ReActAgent + FunctionTool,
来演示思考 → 调用工具 → 观察结果 → 再思考这一套 Data Agent 的工作节奏。
比如,下面的例子给了一个最简单的 FunctionTool:
# 定义一个简单的工具函数
def multiply(a: int, b: int) -> int:
"""Multiply two integers and returns the result integer"""
return a * b
# 把函数封装成工具
multiply_tool = FunctionTool.from_defaults(fn=multiply)
# 初始化 ReAct Agent,并注入工具
agent = ReActAgent.from_tools([multiply_tool], llm=llm, verbose=True)
agent.chat("What is 2123 * 215123")
Agent 内部会经历类似下面的过程(这里只是示意):
Thought: 我需要用一个工具来帮我计算乘法。
Action: multiply
Action Input: {'a': 2123, 'b': 215123}
Observation: 456706129
Thought: 我已经拿到计算结果,可以直接回答用户问题。
Answer: 2123 multiplied by 215123 equals 456706129.
从外面看,我们只是“问了一个问题”。
从里面看,Agent 实际上经历了:思考 → 调用工具 → 观察 → 再思考 → 回答。
Agent 落地
如果你想基于这些概念,搭一个自己的 LLM Agent 或 DataAgent,大致可以按下面几个方向推进:
-
先选一个清晰的任务场景
比如:“帮我查某家公司最新财报并给出要点摘要”
或者:“在多个数据库之间串联查询,生成一份业务日报”
-
列出可用工具和数据源
哪些 API 可以被调用?
有哪些数据库或知识库?
是否需要写入/更新数据?
-
设计基本的规划逻辑
能否通过 CoT 分解任务?
需要用到 ReAct 这种“边做边改”的模式吗?
-
搭建记忆模块
短期:合理设计对话上下文,避免 prompt 膨胀
长期:把关键日志、总结写入向量库,后续可检索复用
-
选择框架实现
如果重点是“数据交互”,可以尝试 LlamaIndex 的 DataAgent
如果更偏工具编排,也可以结合 LangChain、OpenAI function calling 等方案
参考资料
- LLM Agents – Nextra https://www.promptingguide.ai/research/llm-agents
- ReAct 技术介绍 https://www.promptingguide.ai/techniques/react