 lane4dev
lane4dev
当下主流 LLM API 调用价格比较说明
大模型 API 的价格这两年是真·杀疯了,国内厂商一轮轮卷价,美国厂商一轮轮降价。 对做工程落地的人来说,同一份文档丢给不同模型,成本可以差一个数量级,不算清楚,很容易烧钱烧心。
这篇小文就用一个固定场景,来直观对比几家常见 LLM 的调用成本,并给出一些选型上的实用建议。
统一对比场景
为了让不同厂商的价格有可比性,我们先约定一个统一的“样本文档”:
样本:某风电项目可行性研究报告 约
169,880个中文字符(接近 17 万字)
为了方便对比,下面先粗略按 1 个中文字符 ≈ 1 个 token 估算,整份报告大约是:
- 约 170k tokens
-
换算为:
- 以「每千 tokens 计费」:约 170 份“千 tokens”
- 以「每百万 tokens 计费」:约 0.17 份“百万 tokens”
对于现在主流的大模型(GPT-4o、Qwen、GLM 等),实际通常是
1 个 token ≈ 1.3–1.8 个汉字,
所以真实 token 数往往会比这里的估算少 20%–40% 左右,
但不影响不同模型之间的大致价格梯度。
下面所有价格示例,都是把这份报告完整丢给模型做一次分析/总结的单次费用,方便一眼感受“同一件事不同家要花多少钱”。
⚠️ 提醒: 下文价格都以近期公开定价为参考,具体以各家最新官网价格为准。不同计费档位、活动折扣,也会让实际价格略有差异。
文心一言(ERNIE)
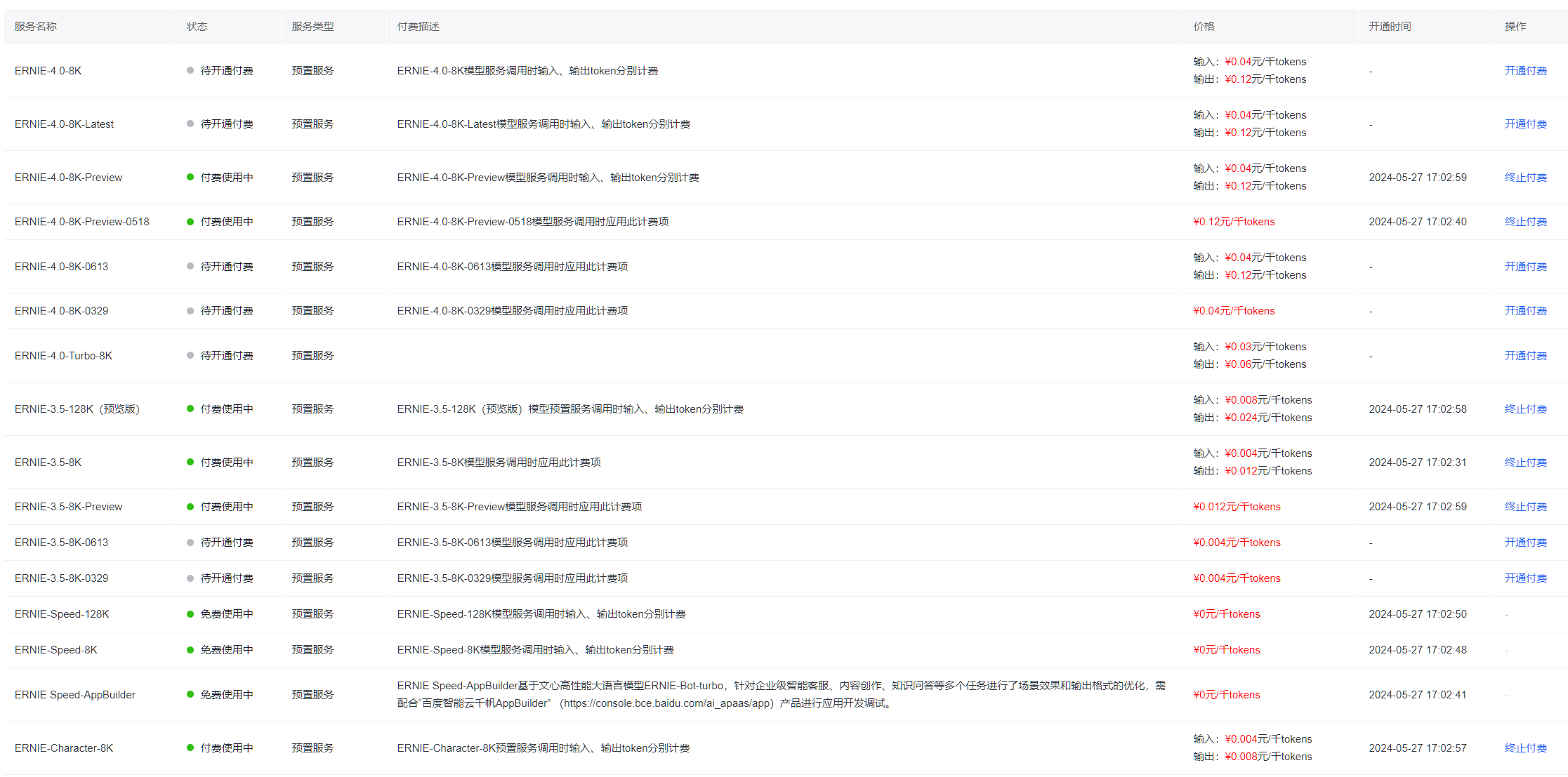
在国内厂商里,文心一言是比较早一批开放 API 的平台之一,主力模型之一是 ERNIE-4.0-8K。
示例价格(输入侧)
- ERNIE-4.0-8K:约 ¥ 0.04 / 千 tokens(示例档位)
- 样本文档约 170k tokens
- 单次输入费用 ≈ 6.79 元
简单算一下:
170(千 tokens) × 0.04 元 ≈ 6.8 元
也就是说,一整本十几万字的风电可研报告,扔给 ERNIE-4.0-8K 让它通读+总结,输入侧大概 7 块钱以内搞定(不计输出 tokens)。



智谱 AI(GLM 系列)
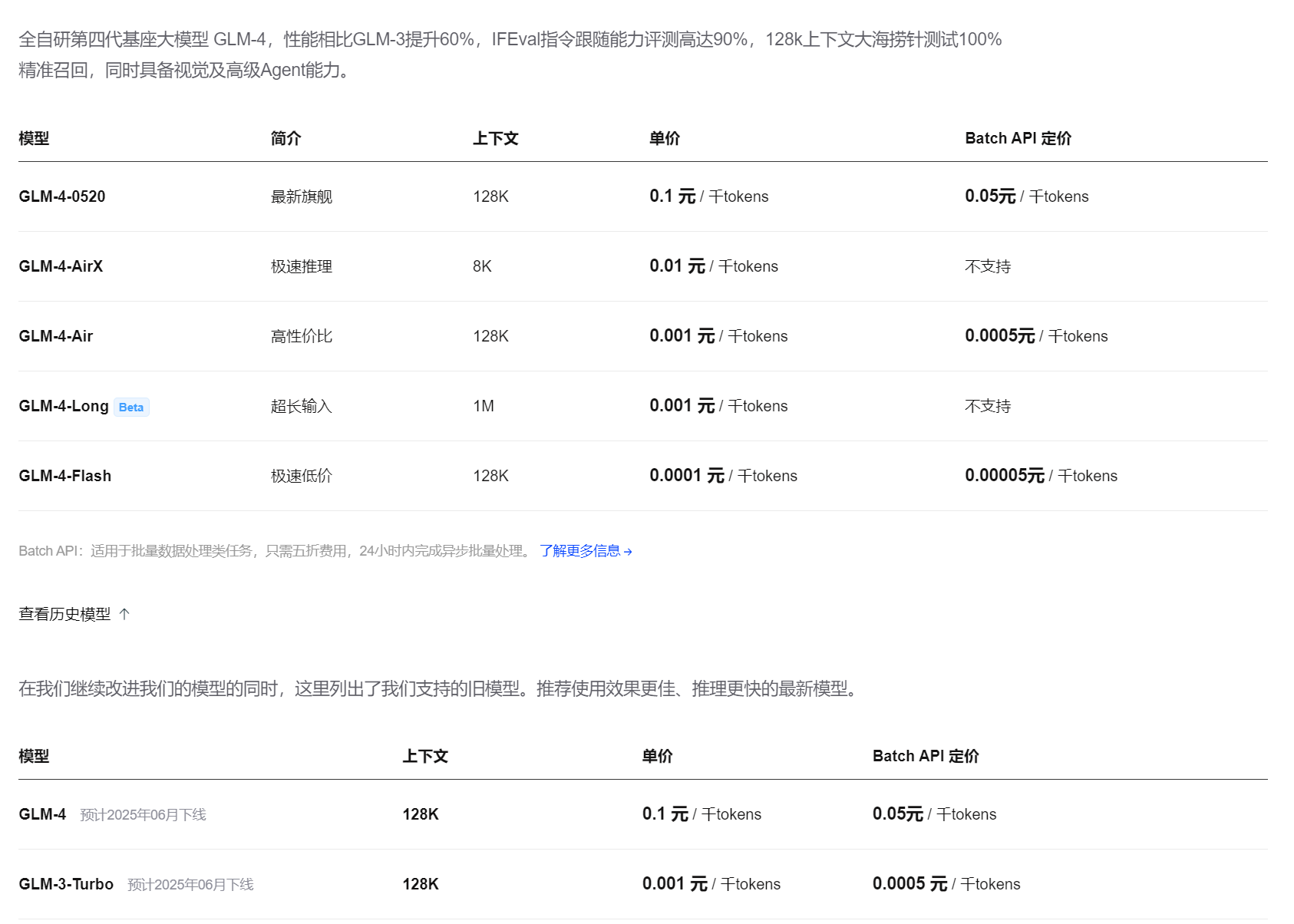
智谱这两年主打 GLM-4 / GLM-4-Long / GLM-4-Air / GLM-4.5-Air 等多个价位梯度的模型,特点是型号多、价格区间跨度大。
以两个具有代表性的模型为例:
-
GLM-4-0520
单价示例:¥ 0.10 / 千 tokens
样本报告费用 ≈
170 × 0.10 = 16.99 元 -
GLM-4-Air
单价示例:¥ 0.001 / 千 tokens
样本报告费用 ≈
170 × 0.001 = 0.17 元
两者对比非常直观:
- 同一份风电可研报告: GLM-4-0520 ≈ 17 元,GLM-4-Air 只要几毛钱。
这就是“同平台内,高性能模型和性价比模型的差价”: 如果只是做批量结构化提取/粗粒度摘要,Air 类模型往往已经够用; 如果需要复杂推理、严苛质量,才值得上到旗舰档。
通义千问(Qwen)
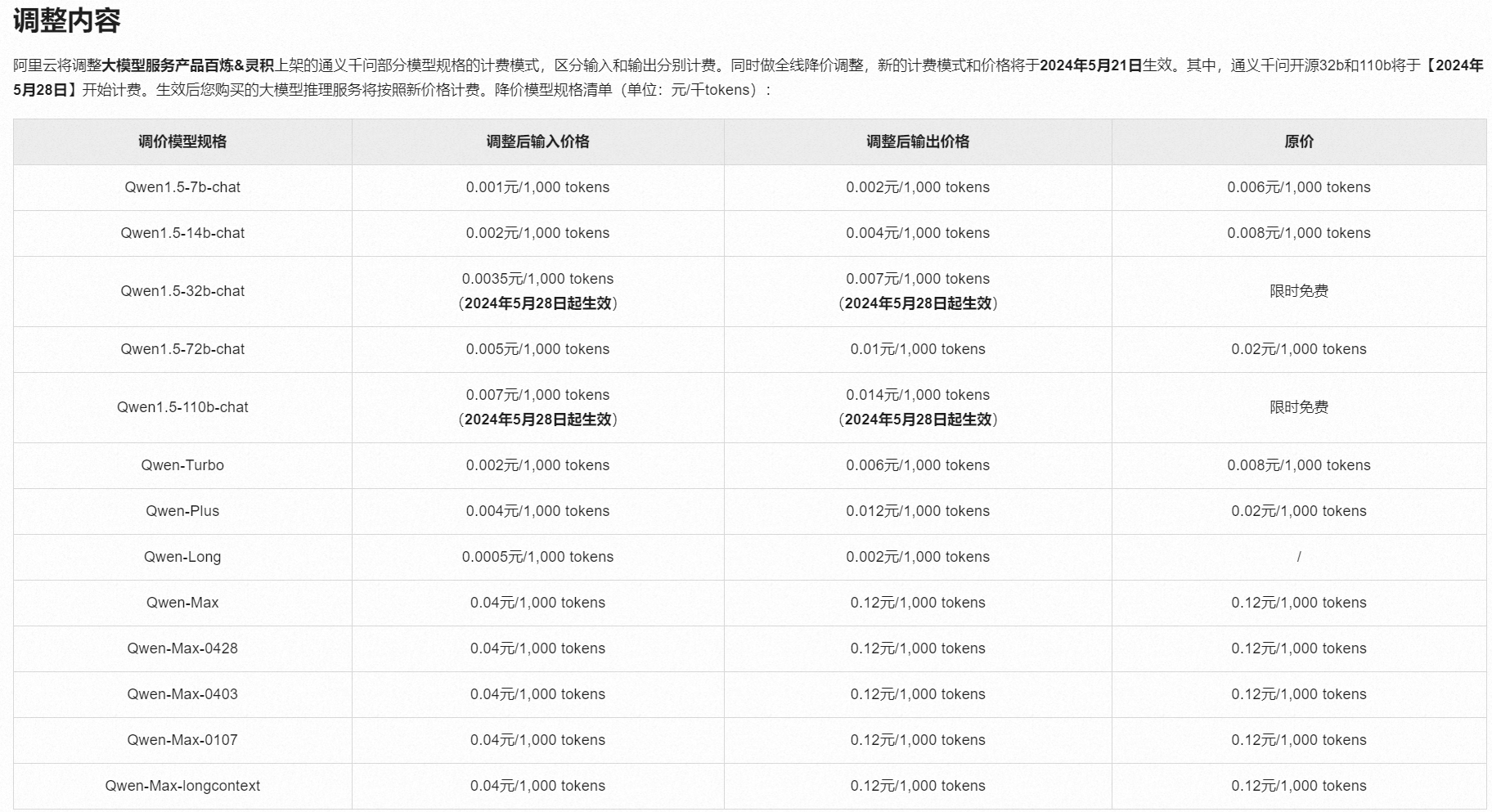
阿里这波在价格战里算是“主角”,尤其是 Qwen-Long 大幅降价之后,长文本成本直接打到地板价。
两档典型模型:
-
Qwen-Long(主打长文本)
输入单价约:¥ 0.0005 / 千 tokens
样本报告费用 ≈
170 × 0.0005 ≈ 0.08 元也就是:一整份可研报告不到 1 角钱
-
Qwen-Max(偏高性能)
输入单价示例:¥ 0.04 / 千 tokens
样本报告费用 ≈
170 × 0.04 ≈ 6.8 元
可以看到:
极致便宜档:Qwen-Long 等长文本模型,适合海量文档粗加工
中高价档:Qwen-Max 等,更适合对答质量要求高的核心流程
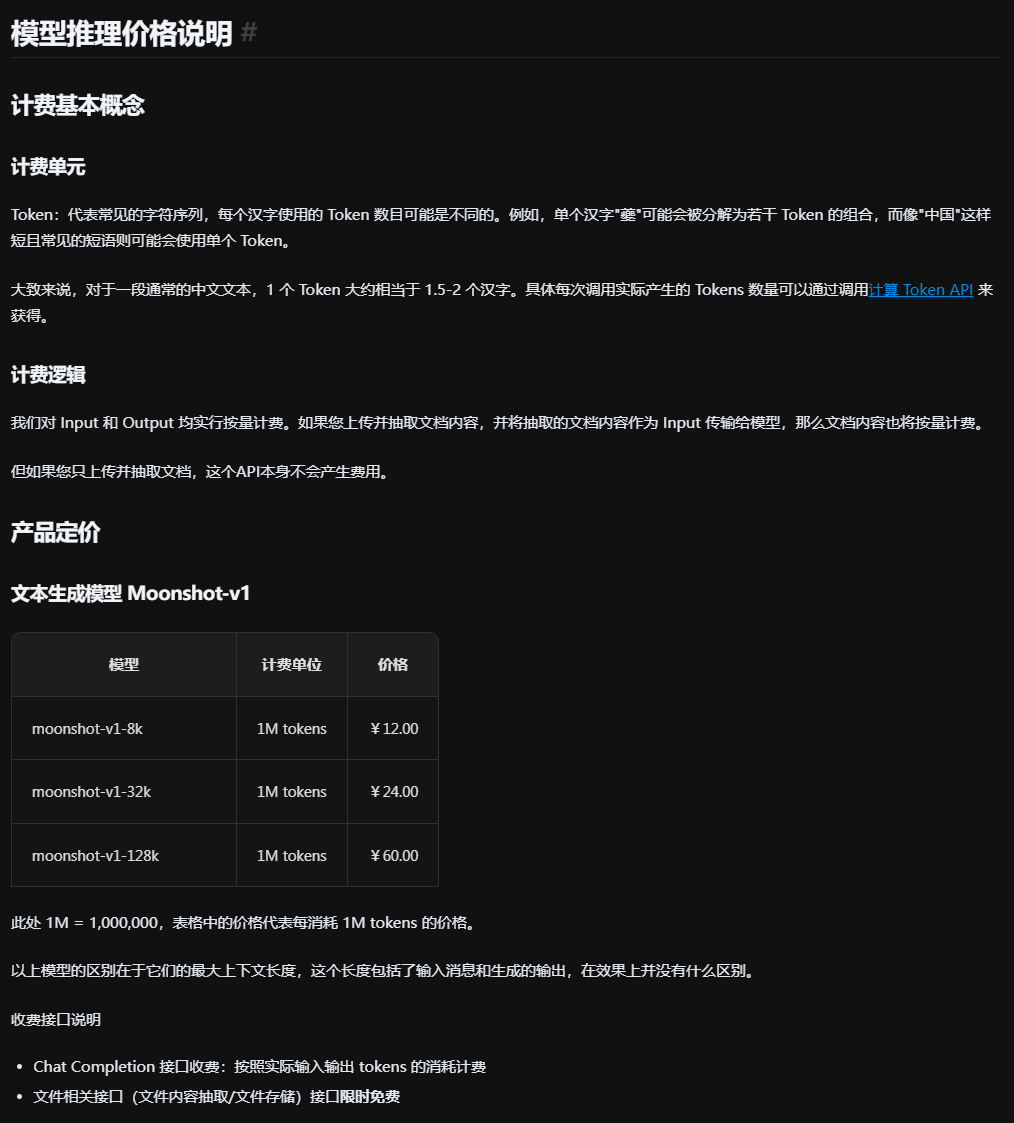
Moonshot AI(Kimi 系列)
Moonshot/Kimi 的几个主力模型一般按 “每百万 tokens” 计价,比如 moonshot-v1-8k / 32k / 128k 等。
以两个常见模型为例:
-
moonshot-v1-8k
输入单价示例:¥ 12 / 百万 tokens
样本报告费用 ≈
0.17 × 12 ≈ 2.04 元 -
moonshot-v1-128k
输入单价示例:¥ 60 / 百万 tokens
样本报告费用 ≈
0.17 × 60 ≈ 10.19 元
在同样读取整份可研报告的前提下:
8k 档:能覆盖部分截断/分段处理场景,价格相对亲民
128k 档:上下文极长,适合“整本喂给模型不想切块”的懒人用法,但要付出对应的价格
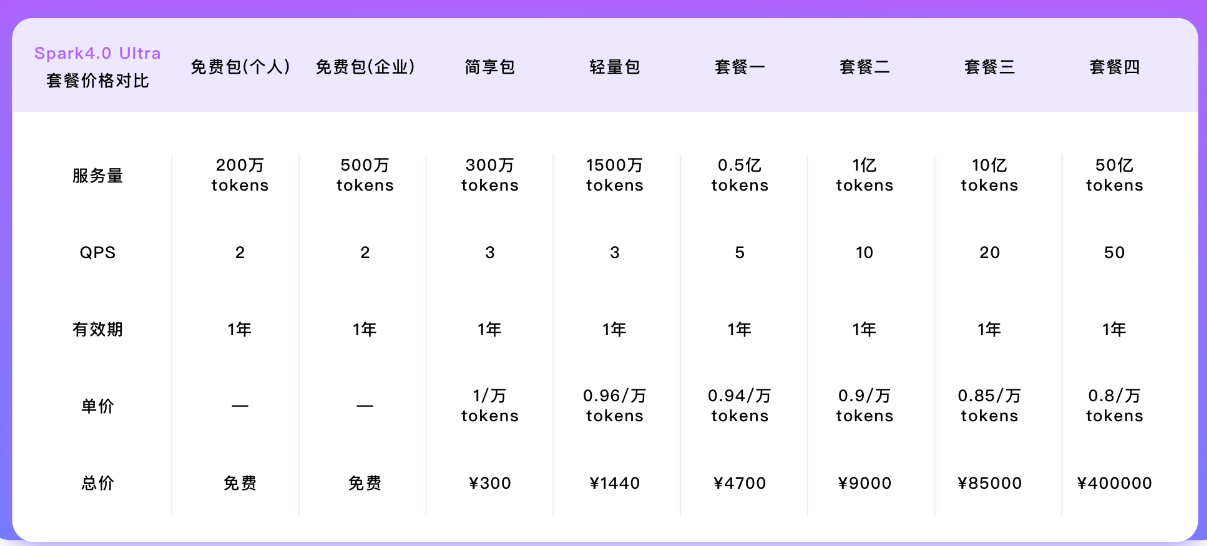
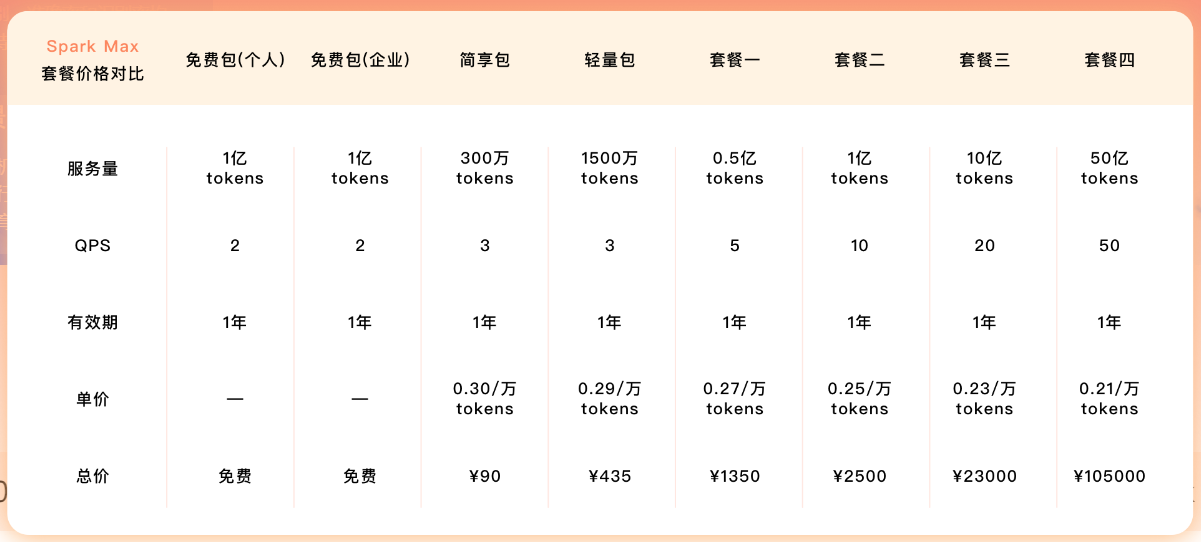
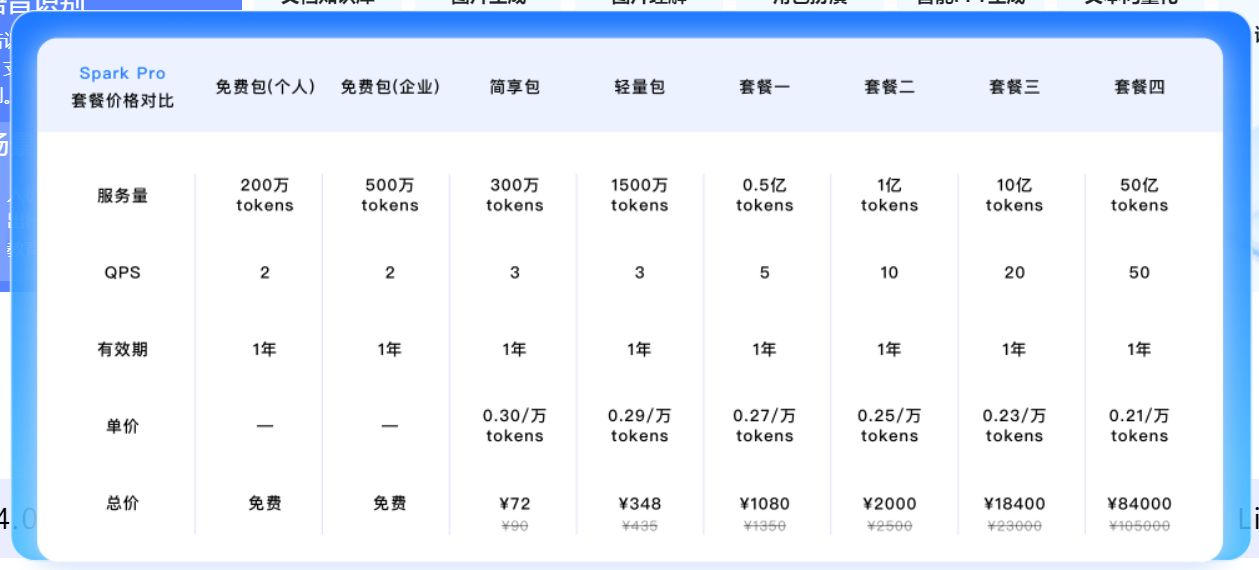
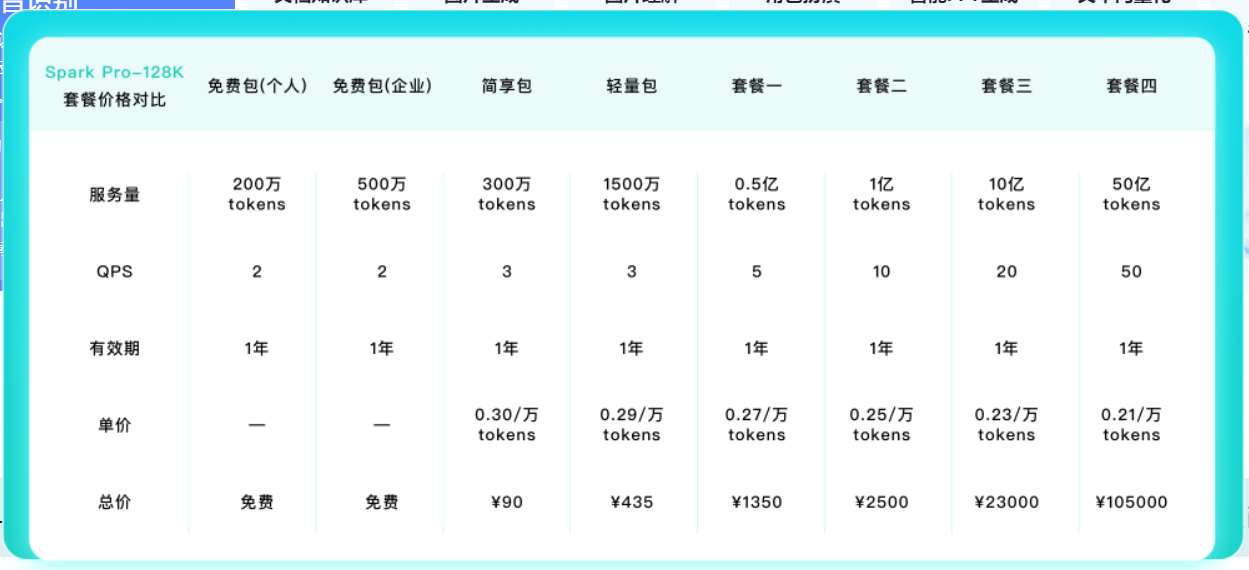
讯飞星火(Spark)
星火的部分模型经常以“万 tokens”为计费单位,并提供多档性能组合,典型如 Spark-Pro-128k 和更高规格的 QSpark 4.0 Ultra 等。
以两档代表性档位为例:
-
Spark-Pro-128k
单价示例:¥ 0.3 / 万 tokens
样本报告 ≈ 16.99 个“万 tokens”
费用 ≈
16.99 × 0.3 ≈ 5.10 元 -
QSpark 4.0 Ultra
单价示例:¥ 1 / 万 tokens
同一份报告费用 ≈
16.99 × 1 ≈ 16.99 元
整体来看,星火的定价大致介于“极致低价”的长文本模型与高性能国际模型之间,既能覆盖中文场景,又在一些细分行业(教育、政企)有完整的生态和 SDK。
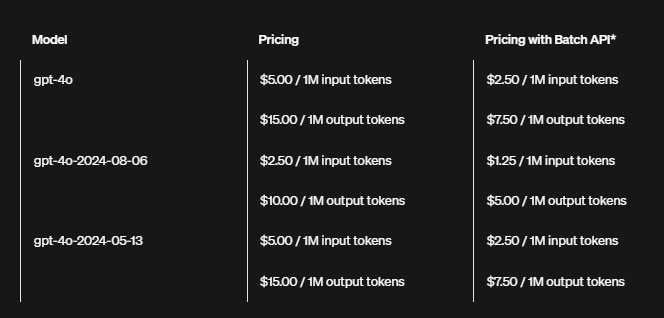
OpenAI(gpt-4o / gpt-4o-mini 等)
在海外生态中,OpenAI 依旧是“定价锚点”之一。以常见的 gpt-4o 和 gpt-4o-mini 为例,它们一般按照 “美元 / 百万 tokens” 来报价。
以大致汇率 1 美元 ≈ 7.2 元人民币 为参考:
-
gpt-4o-mini
输入单价:$0.15 / 百万 tokens
样本报告输入费用:
0.17 × 0.15 ≈ 0.0255 美元 ≈ 0.18 元 -
gpt-4o
输入单价示例:$5 / 百万 tokens(不同批次略有调整)
样本报告输入费用:
0.17 × 5 ≈ 0.85 美元 ≈ 6.12 元
所以如果你通过代理平台/聚合网关在国内调用 OpenAI,一份十几万字的可研报告:
走 gpt-4o-mini:大约几毛钱级别
走 gpt-4o:大约 6 元左右

横向对比:同一份可研报告,大概要花多少钱?
基于上面的示例,我们可以把“读完一份约 17 万字风电可研报告”的输入侧成本粗略归纳成几档(单位:人民币):
同一份报告,单次调用的大致输入费用:
-
极致便宜档(分厘级)
- Qwen-Long、GLM-4-Air、gpt-4o-mini 等:
- 约 0.08 ~ 0.3 元 量级,就能让模型完整看完一份可研。
-
中等价位档(几块钱)
- 文心 ERNIE-4.x、Qwen-Max、moonshot-v1-8k、Spark-Pro-128k、gpt-4o 等:
- 一次调用大约 2 ~ 7 元。
-
偏高价档(十几元)
- 强性能/超长上下文档位,如 GLM 高配档、Moonshot-128k、星火高端档:
- 单次调用可能来到 10 ~ 20 元 甚至更高。
一个直观结论:
在“让模型完整读一遍可研”的场景里,
不同模型的输入成本差不多可以拉开 100 倍左右的差距。
如果要做的事情是“每天几百份可研报告自动解析”,选错价位,相当于每天拿项目预算给 API 点蜡。
9. 工程实践中的选型建议
最后,结合上面的数字,给几个比较接地气的小建议:
9.1 把“读”和“想”拆开
-
读文档 / 结构化抽取 / 初步概括
- 可以优先用 长文本、性价比模型(Qwen-Long、GLM-4-Air、gpt-4o-mini 等),一大批文档跑下来价格非常可控。
-
关键结论 / 逻辑复核 / 生成对外材料
- 再把抽取好的结构化结果,扔给 高性能模型(gpt-4o、ERNIE-4.x 高配档、Moonshot 高配档等),做精细推理和润色。
-
这样组合,往往能做到:
绝大部分 tokens 用在便宜模型上,只有“最后那几步”用贵模型兜底。
9.2 别只看单价,记得算“场景总价”
有些模型单价便宜,但需要反复重试、提示词很长,实际总 tokens 用量会被放大。
有些模型单价略高,但一次到位、思考能力强,整体算下来可能更省钱。
简单做一张 Excel,把真实场景的条件考量在内:
- 每次平均输入 tokens
- 每次平均输出 tokens
- 每天/每月调用次数 带进去算一算,很快就能看出哪家是真的便宜。
9.3 长文本 ≠ 一定要“整本一次性喂”
风电可研这类文档往往结构明确(总论、资源条件、技术方案、投资估算、经济评价……):
可以考虑 按章节切块, 用便宜的长文本模型逐块分析,再用高性能模型整合总结。
这样做不仅便宜,还能让你更精细地控制“哪些章节要算得更细、哪些只要粗看”。
9.4 定期回顾价格表
过去两年,各家价格变化非常剧烈:
有厂商直接把长文本模型输入价从 0.02 元/千 tokens 降到 0.0005 元/千 tokens;
也有厂商推出新一代模型,输入价只有上一代的一小部分;
所以非常建议:
每季度至少打开一次各家价格页面, 看看有没有更便宜的新型号, 顺手把你系统里的“默认模型”调一调。
10. 小结
如果只看“官方价格表”,你会看到一堆 0.000x、¥0.xx/千 tokens 或 $0.x/百万 tokens,既抽象又难比较。
一旦统一到“让模型完整读一份风电可研报告,要花多少钱?”这个具体问题,在我自己的工作过程中,差距就清晰了:
几毛钱就能跑通的模型,可以大胆用在高频、批处理场景,
几块到十几块一次的模型,更适合关键节点、对质量极其敏感的环节。