 lane4dev
lane4dev

QAnything 的定位,是一个本地知识库问答系统,支持多种文件格式、离线部署和两阶段检索 rerank。 本篇我们不从“架构宣传图”开始,而是沿着源码,顺着三条主线把系统拆开看:
- 启动流程:从一行 Shell 一路走到 Sanic 服务和 LocalDocQA。
- 文档上传流程:文件是怎么变成向量库里的分片的。
- 问答流程:一次
/local_doc_chat背后到底跑了什么。
中间会顺带看看数据库表结构、OCR、Faiss、rerank/embedding 这些关键组件。
启动流程
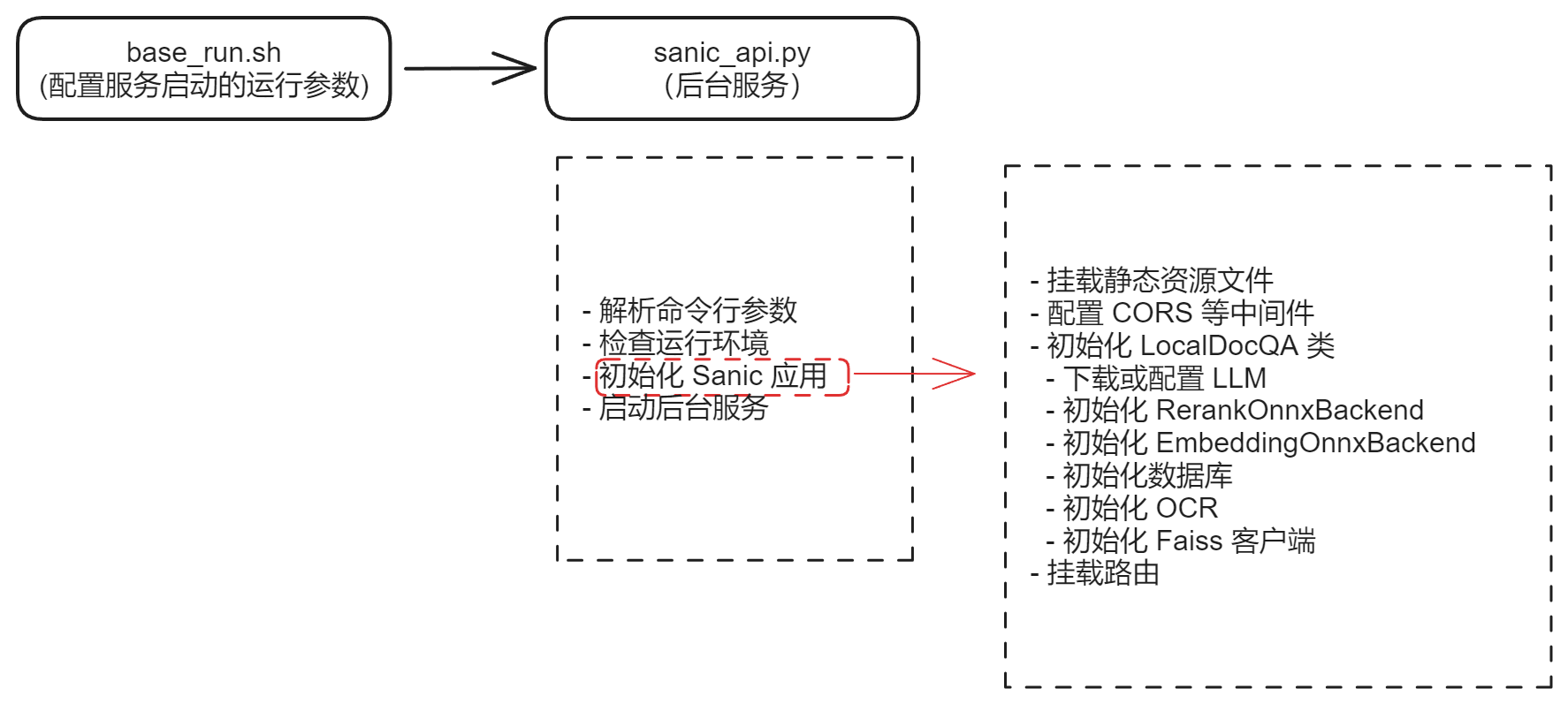
Shell 入口:run_for_3B_in_Linux_or_WSL.sh
QAnything 的典型启动命令非常“运维友好”,是一个 Bash 包装脚本:
#!/bin/bash
bash scripts/base_run.sh -s 'LinuxOrWSL' -m 19530 -q 8777 -M 3B
这里只是把常用参数(系统类型、Milvus 端口、QAnything 端口、模型尺寸等)预设好,全都继续交给 base_run.sh 处理。
base_run.sh
base_run.sh 做两件事:
-
解析参数
包括:
system:操作系统(Linux / WSL)milvus_port:向量库端口(如果用)qanything_port:后端服务端口model_size:模型大小(例如 3B)use_cpu:onnxruntime 用 GPU 还是 CPUuse_openai_api、openai_api_base、openai_api_key等在线 LLM 的设置workers:Sanic worker 数(目前代码里被注释掉,默认单 worker)
-
最终启动后端服务
CUDA_VISIBLE_DEVICES=0 python3 -m qanything_kernel.qanything_server.sanic_api \ --host 0.0.0.0 --port $qanything_port --model_size $model_size \ $use_cpu_option $use_openai_api_option \ ${openai_api_base:+--openai_api_base "$openai_api_base"} \ ${openai_api_key:+--openai_api_key "$openai_api_key"} \ ${openai_api_model_name:+--openai_api_model_name "$openai_api_model_name"} \ ${openai_api_context_length:+--openai_api_context_length "$openai_api_context_length"} \ ${workers:+--workers "$workers"}
从这里开始,控制权交给 Python 模块 qanything_kernel.qanything_server.sanic_api。
环境检测 + Sanic 应用初始化
sanic_api.py 文件的逻辑可以概括为 4 步:
-
解析命令行参数(argparse)
负责把上一步 shell 传来的
model_size、OpenAI 配置等全部接管。 -
环境和依赖检查
- CUDA 版本(≥ 12.0,且当前使用 GPU 时才检查);
- 运行平台必须是 Linux / WSL;
glibc≥ 2.28;onnxruntime安装且版本满足最低要求(用于 embedding / rerank);- 若启用在线 OpenAI 服务,要求
vllm≥ 0.2.7(本地模型服务)。
这一步其实是安装文档里那堆前置条件的自动化守门员。
-
模型准备 + LocalDocQA 初始化
-
检查对应尺寸的本地模型是否存在,不在就下载到
assets/custom_models。 -
初始化
Sanicapp,并做几件关键事:
-
挂载静态资源:前端 Web 界面
app.static( '/qanything/', 'qanything_kernel/qanything_server/dist/qanything/', name='qanything', index="index.html" ) -
初始化 CORS、中间件
-
初始化
LocalDocQA并挂到app.ctx这是整个 RAG 流程的心脏,后面的 API(上传、问答)都围绕它转。 -
注册一组 REST 路由(知识库 & Bot 管理):
app.add_route(new_knowledge_base, "/api/local_doc_qa/new_knowledge_base", methods=['POST']) app.add_route(upload_files, "/api/local_doc_qa/upload_files", methods=['POST']) app.add_route(local_doc_chat, "/api/local_doc_qa/local_doc_chat", methods=['POST']) # 以及 list_kbs / list_files / delete_files / new_bot / upload_faqs / get_qa_info 等
-
-
启动 Sanic 服务
最终通过
app.run(host, port, workers=...)把整个后端服务拉起来。
到这一步为止,我们已经从一行 Bash顺利走到了一个挂着 LocalDocQA 的 Sanic Web 服务。
LocalDocQA 初始化
qanything_kernel/core/local_doc_qa.py::LocalDocQA 在启动时做了大量准备工作,可以拆成几块看。
分别是 LLM, 向量检索, OCR 和 数据库。
基本参数
rerank_top_k会根据model_size设置为 3 或 7,用于控制二阶段重排后保留多少候选片段。- 这是速度 vs 效果的一个简单平衡开关,更大的模型通常可以用更少的片段做出不错的回答。
LLM 封装
LocalDocQA 支持两种 LLM 后端:
-
OpenAILLM对官方
openai.OpenAISDK 的简单包装, 用于直连在线 OpenAI 服务(或兼容 API)。 -
OpenAICustomLLM使用
vllm加载本地大模型,并提供与 OpenAI 类似的接口风格, 对上层来说,“线上 API”与“本地 vLLM”基本是同一套调用方式。
这层抽象的意义在于:问答流程不用关心模型部署方式,只需要一个 Chat Completion 风格的接口就够了。
向量检索
QAnything 的检索是标准的两阶段结构:先向量检索,再 rerank。
-
EmbeddingOnnxBackend
- 模型目录:
qanything_kernel/connector/embedding/embedding_model_configs_v0.0.1 - 模型名称:
netease-youdao/bce-embedding-base_v1 - 使用
onnxruntime加载,负责将文本(query 和文档分片)转成向量。
- 模型目录:
-
RerankOnnxBackend
- 模型目录:
qanything_kernel/connector/rerank/rerank_model_configs_v0.0.1 - 模型名称:
netease-youdao/bce-reranker-base_v1 - 同样基于
onnxruntime,根据 query + 文本片段打出相关性分数,通常在 0–1 之间(BCE 风格)。
- 模型目录:
在实践上,这意味着:
Faiss 只负责“粗排”:从海量分片里捞出一批可能相关的候选, Rerank 再根据语义细节做“精排”:把真正回答问题的那几块片段提到前面。
SQLite 数据库
数据库文件路径为 QANY_DB/qanything.db,通过 create_tables_ 一次性建好所有表,包括:
User:用户信息KnowledgeBase:知识库列表(与用户关联)File:文件级信息,包含状态、大小、分片长度、存储路径等Document:分片与文件、知识库之间的映射QanythingBot:自定义 Bot 配置(prompt、模型、关联 kb 等)Faqs:FAQ 对(问答对)存储QaLogs:完整的问答日志(query、模型、结果、检索到的文档等)
这些表构成了 QAnything 的“控制面板”: 文件和知识库的生命周期、Bot 行为、问答调用的所有关键信息,都能在这里追踪。
OCR
QAnything 内置了一套 OCR 流程,用于解析 PDF 扫描件、图片等:
-
模型路径:
qanything_kernel/dependent_server/ocr_server/ocr_models -
创建
self.ocr_reader = OCRQAnything(model_dir=OCR_MODEL_PATH, device="cpu")(特意放在 CPU 上,以节省显存) -
OCRQAnything内含:TextDetector:负责找出文字区域(边界框)TextRecognizer:对区域内的文字做识别
通常会根据检测结果的文本方向、置信度等来判断是否需要旋转页面,这一块适合单独再做一次源码追踪。
Faiss 向量库
向量库由 FaissClient 负责管理,初始化时需要:
- 一个
mysql_client(用于存储向量元数据、索引映射等); - 一个
embeddings实例(即上面的 EmbeddingOnnxBackend)。
文件存储结构:
- 根目录:
QANY_DB/faiss - 每个知识库一个子目录:
QANY_DB/faiss/{kb_id}/faiss_index
检索时通过:
self.faiss_client.asimilarity_search_with_score(
query, k=top_k, filter=filter, fetch_k=200
)
在 L2 空间里找到最近的向量,再结合 rerank 分数做综合排序。
文档上传流程
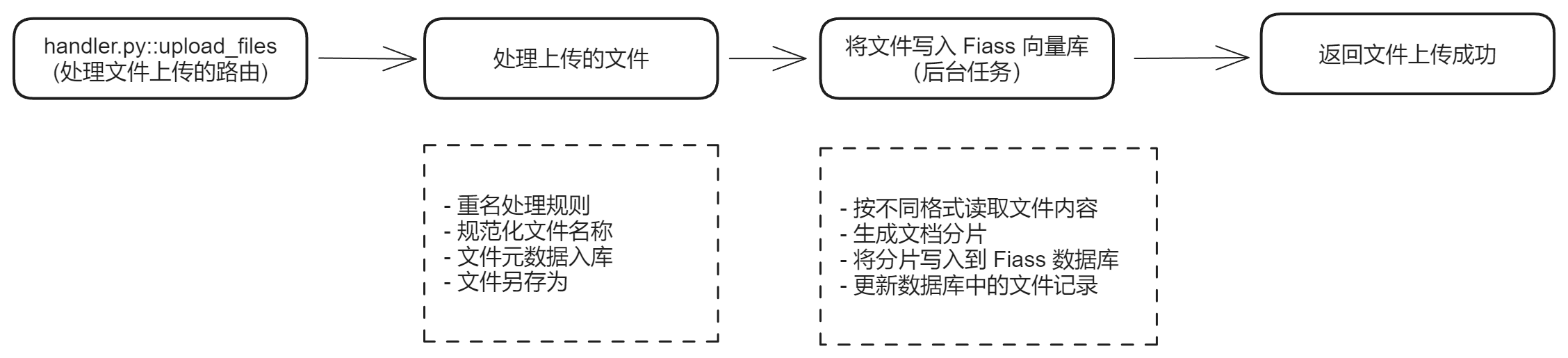
上传入口是 REST API:
POST http://{your_host}:8777/api/local_doc_qa/upload_files
请求参数与基本约束
Body(multipart form-data)核心字段:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| files | File | 是 | 支持多文件,[md, txt, pdf, jpg, png, jpeg, docx, xlsx, pptx, eml, csv] |
| user_id | String | 是 | 用户 ID(默认常见示例为 zzp) |
| kb_id | String | 是 | 知识库 ID |
| mode | String | 否 | soft/strong,同名文件是否覆盖,默认 soft |
后端处理步骤
-
取出 LocalDocQA
从
app.ctx里读出在启动阶段初始化好的local_doc_qa实例。 -
文件列表构建
支持上传的文件(form-data)。 同时也可以读取项目根目录下
data目录内的本地文件。mode = soft时遇到同名文件直接跳过;mode = strong则强制上传(覆盖)。 -
文件名规范化
去掉全角字符、斜杠
/等不安全字符, 这一步能避免后续存储路径或数据库字段出错。 -
写入数据库
在
File、Document等表里记录文件的元信息(状态、时间戳等), 初始化时,分片大小、内容长度等信息还未填充,后续由后台任务补全。 -
封装为
LocalFile创建
LocalFile对象时,会把文件物理拷贝/保存到:QANY_DB/content/{user_id}/... -
后台任务:写入 Faiss
调用
local_doc_qa.insert_files_to_faiss作为后台任务运行,整体流程包括:-
读取文件内容(多种格式):
Excel 通过
pandas读表, MP3 走Whisper语音转文本,URL / FAQ / md / txt / pdf / image等都有对应解析器。 - 按策略切分成文本分片(chunk)
- 对每个分片做 embedding,并写入 Faiss 索引
- 回写数据库:文件大小、分片数、Faiss 写入状态等字段
-
-
返回结果
返回每个文件的上传结果、知识库 ID、基础状态信息等。
问答流程
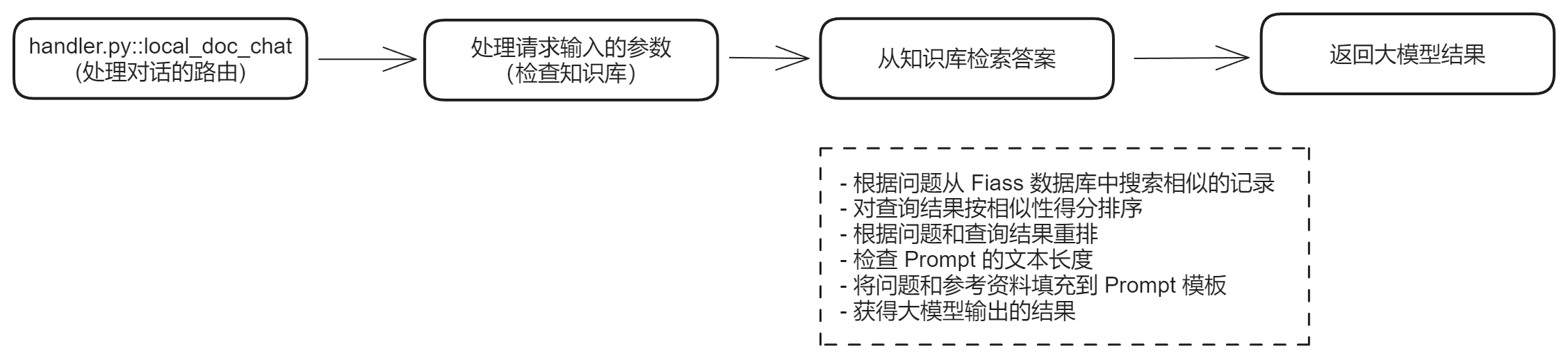
问答入口:
POST http://{your_host}:8777/api/local_doc_qa/local_doc_chat
请求参数
| 参数名 | 示例 | 必填 | 类型 | 说明 |
|---|---|---|---|---|
| user_id | “zzp” | 是 | String | 用户 ID |
| kb_ids | [“KB1”, “KB2”] | 是 | Array | 支持多知识库联合问答 |
| question | “保险单号是多少?” | 是 | String | 用户问题 |
| history | [[“q1”,”a1”], …] | 否 | Array[Array] | 对话历史 |
| rerank | True | 否 | Bool | 是否开启二阶段重排 |
| streaming | False | 否 | Bool | 是否流式输出 |
| networking | False | 否 | Bool | 是否联网检索 |
| custom_prompt | “…编程机器人…” | 否 | String | 自定义角色 Prompt |
后端问答步骤
-
取出 LocalDocQA
同上传流程,先从
app.ctx取到local_doc_qa。 -
检查知识库与文件状态
从数据库中读出所有选定
kb_ids下的文件信息, 确认所有文件都已完成 Faiss 写入;否则提示“知识库为空”或“索引未完成”。 -
向量检索:Faiss + 过滤
使用文本 query:
docs = await self.faiss_client.search( kb_ids, query, filter=filter, top_k=top_k )底层是 L2 距离检索(Faiss
IndexFlatL2(768)),相似度需要根据具体实现映射。 -
结果排序与 Rerank
先按向量相似度做初筛。
如果分片数量 > 1,则结合
bce-reranker按 query 重排: 通常会设置一个分数阈值(如 > 0.35)过滤掉低相关片段。最终保留若干最相关上下文(由
rerank_top_k控制)。 -
构造 Prompt
将筛选后的上下文拼接成
context,再与用户问题、历史对话等填入固定模板:PROMPT_TEMPLATE = """参考信息: {context} --- 我的问题或指令: {question} --- 请根据上述参考信息回答我的问题或回复我的指令。前面的参考信息可能有用,也可能没用,你需要从我给出的参考信息中选出与我的问题最相关的那些,来为你的回答提供依据。回答一定要忠于原文,简洁但不丢信息,不要胡乱编造。我的问题或指令是什么语种,你就用什么语种回复, 你的回复:"""在填充前会检查总 token 数:超出模型上下文长度就裁剪 context。
-
调用 LLM
将最终 Prompt + 可选
custom_prompt发送给 LLM(在线 OpenAI 或本地 vLLM)。支持 streaming 模式时,以流式返回 tokens 给前端展示。
-
记录日志并返回
在
QaLogs表中记录本次会话的详细信息:- query、answer、模型名称
- 参与检索的
kb_ids - time_record、history、condense_question、完整 prompt
- retrieval_documents / source_documents(便于调试检索效果)
将最终回答和引用片段信息返回给前端。
一些值得继续追的技术问题
-
OCR 旋转逻辑
OCRQAnything中TextDetector是如何判断 PDF 页面需要旋转的? 后续考虑直接追踪:load_model(model_dir, 'rec')与load_model(model_dir, 'det')的具体实现。 -
分片策略与 top_k
当前配置中
VECTOR_SEARCH_TOP_K = 40,但有两个问题:- 实际 chunk 长度是否固定?
- 是否有针对文档分片过长的特殊处理?超长时如何二次切分?
-
其他优化
- 控制上下文长度:是否需要做“片段摘要 + 元数据(标题、文件名、页码)”混合?
- 引入 Markdown 格式,让引用的上下文更易阅读。
- 针对长对话,引入问题重构(query rewrite)逻辑。
-
模型替换
中提到的 MiniCPM、QWen 2B 等本地模型,未来是否可以接入到
OpenAICustomLLM封装,保持上层接口不变的前提下试不同 LLM。
小结
整套 QAnything 源码走下来,可以看到它其实是一个“RAG 工程落地范例”:
- 用 Shell 脚本把复杂的环境参数收拢成一条命令;
- 用 Sanic + LocalDocQA 把 Web API 与底层 LLM/向量检索/OCR 串成一个统一服务;
- 通过 SQLite + Faiss + onnxruntime,把
文件 → 分片 → 向量 → 回答这条链路打通; - 再加上 Bot、FAQ、日志这些配套设施,让系统能够真的跑在生产环境。