使用 Darts + DeepAR 进行风电功率时间序列预测实战
这篇文章演示如何使用 Darts 库,结合 DeepAR 思路(基于 RNN 的概率预测模型),对风电场的发电功率做短期预测。
示例数据来自 Bangaluru Wind Generation 2017–2021,包含 2017–2021 年的逐时发电功率记录。
我们的目标可以总结为一句话:
利用过去一段时间的功率变化和时间特征(年、月、日),预测未来 48 小时的风电功率,并给出不确定性区间。
环境与库准备
我们使用 Darts 这个时间序列库,它内部已经帮我们封装好了 RNN/DeepAR 模型、数据预处理和评估指标。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.dataprocessing.transformers import Scaler
from darts.models import RNNModel
from darts.metrics import mae, rmse
from darts.utils.statistics import check_seasonality
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.utils.likelihood_models import GaussianLikelihood
import warnings
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
如果你使用 notebook,建议把 matplotlib 的图像显示也打开:
%matplotlib inline
plt.style.use("seaborn-v0_8")
数据加载与基础预处理
数据文件为 Bangaluru_Wind Generation 2017-2021.csv,其中包含一个时间列 Timeseries 和功率列 Power Generated(kw)。
df = pd.read_csv(
"assets/Bangaluru_Wind Generation 2017-2021.csv",
header=0,
parse_dates=["Timeseries"]
)
# 列表中还有一个 id 字段,这里直接删除
df.drop("id", axis=1, inplace=True)
# 将时间列设置为索引
df.index = df["Timeseries"]
# 看一眼统计特征
df.describe()
数据是逐小时记录的吗?即便不是,我们也可以统一按小时重采样,保证时间轴整齐:
# 按 1 小时重采样,使用求和(也可以按实际业务选择 mean/max 等)
df = df.resample("H", convention="start").sum()
转换为 Darts 的 TimeSeries 对象并初步探索
Darts 的大部分模型都操作 TimeSeries 对象,所以先把 DataFrame 转一下:
df_ts = TimeSeries.from_dataframe(
df,
value_cols="Power Generated(kw)",
fill_missing_dates=True, # 填补缺失时间
freq="H" # 明确频率为 1 小时
)
plt.figure(figsize=(21, 9))
df_ts.plot()
plt.title("Bangaluru Wind Power Generation (2017–2021)")

接下来,我们用 check_seasonality 粗略看一下是否存在显著季节性(比如按日、按周的周期):
for m in range(16, 744): # 从 16 到 744 小时尝试不同周期
is_seasonal, period = check_seasonality(df_ts, m=m, max_lag=744, alpha=0.05)
if is_seasonal:
print(f"There is seasonality of order {period}.")
有了这种直觉之后,我们心里大致知道:这个序列是不是有明显的周期性、周期大概多长,对后面选择输入窗口长度有帮助。
划分训练集 / 验证集
我们用 2017–2020 年 的数据训练模型,用 2021 年之后 的数据做验证。代码里是通过时间戳来切分:
train, val = df_ts.split_before(pd.Timestamp("2021-01-01"))
len(train), len(val)
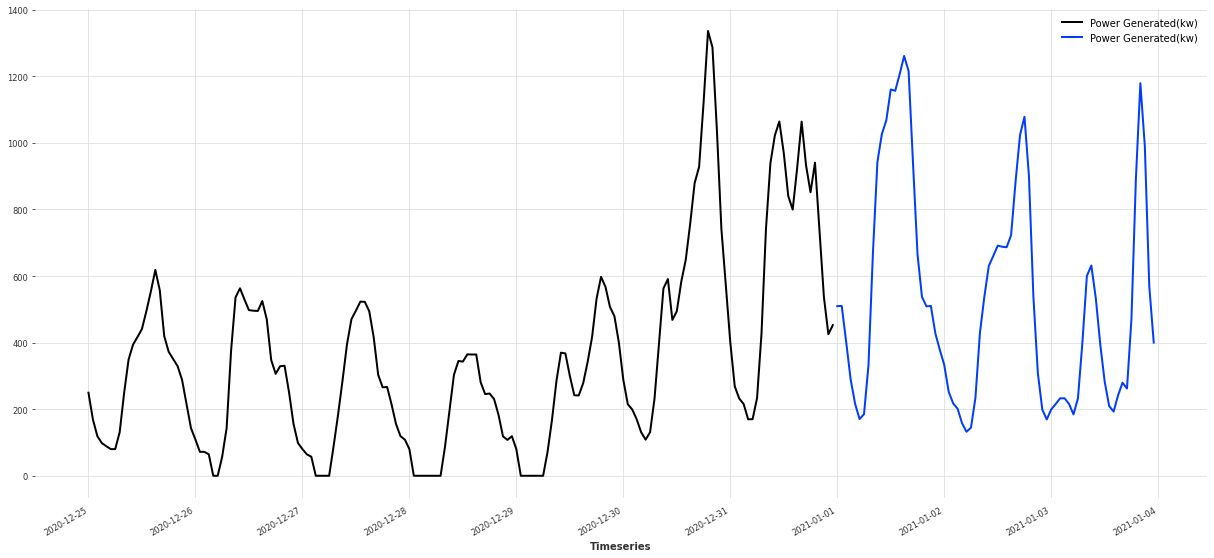
简单把边界附近的走势画出来,看一下训练和验证拼接是否自然:
plt.figure(figsize=(21, 9))
train[-168:].plot(label="train (last 7 days)")
val[:72].plot(label="val (first 3 days)")
plt.legend()
plt.title("Train / Validation split around 2021-01-01")
标准化:让模型更好收敛
深度学习模型对变量的尺度比较敏感,一般都要先做标准化。Darts 提供了现成的 Scaler:
# 仅在训练集上拟合标准化器,避免「偷看」验证集
transformer = Scaler()
train_transformed = transformer.fit_transform(train)
val_transformed = transformer.transform(val)
series_transformed = transformer.transform(df_ts)
这里我们保留了 series_transformed,后面构造时间特征时会用到完整序列。
构造时间协变量(covariates)
DeepAR 的一个优势是可以很自然地接入各种 协变量(covariates):比如时间特征(年、月、日)、天气特征、节假日标记等。本例先从最简单的时间特征开始:
# 基于完整标准化后的时间序列构造时间特征
year_series = datetime_attribute_timeseries(
series_transformed,
attribute="year",
one_hot=False, # 年份通常不用 one-hot
)
# 对年份特征再做一次缩放(保持数值范围合理)
year_series = Scaler().fit_transform(year_series)
# month / day 使用 one-hot,捕捉月份和日期的周期性
month_series = datetime_attribute_timeseries(
year_series, attribute="month", one_hot=True
)
day_series = datetime_attribute_timeseries(
year_series, attribute="day", one_hot=True
)
# 将多个 covariate 按列堆叠
covariates = year_series.stack(month_series).stack(day_series)
# 按同一时间点切分训练和验证协变量
cov_train, cov_val = covariates.split_before(pd.Timestamp("2021-01-01"))
到这一步,我们就有了:
train_transformed:训练目标序列val_transformed:验证目标序列cov_train:训练阶段可用的时间协变量cov_val:验证阶段可用的时间协变量
使用 RNNModel + GaussianLikelihood 搭建 DeepAR 风格模型
在 Darts 中,DeepAR 风格的模型可以通过 RNNModel + 概率分布(likelihood)来实现。这里我们使用:
model="LSTM":LSTM 单元GaussianLikelihood():假定未来值服从高斯分布,模型学习均值和方差training_length = input_chunk_length = 168:用过去 168 小时(7 天)来预测未来一小段时间n_epochs = 100:训练轮数(可根据实际情况调整)
model_en = RNNModel(
model="LSTM",
hidden_dim=24,
n_rnn_layers=2,
dropout=0.2,
batch_size=48,
n_epochs=100,
model_name="DeepAR_model",
optimizer_kwargs={"lr": 1e-3},
random_state=42,
training_length=168, # 训练序列片段长度
input_chunk_length=168, # 每次输入的历史窗口
likelihood=GaussianLikelihood(), # 概率预测的关键
)
从直觉上理解这个模型:
每一次预测时,它都会看过去 168 小时的功率和时间特征,然后输出未来一段时间功率的 概率分布,我们可以从这个分布中采样多条路径,得到预测区间。
训练模型
训练时,把训练集序列和对应的协变量喂给模型,同时把验证集也传进去用于早停/监控:
model_en.fit(
series=train_transformed,
future_covariates=cov_train,
val_series=val_transformed,
val_future_covariates=cov_val,
verbose=False,
)
预测未来 48 小时并可视化结果
我们希望预测 未来 48 小时 的功率,同时利用 DeepAR 的能力给出一个置信区间。num_samples 参数控制从概率分布中采样的轨迹数,采样越多,估出来的区间越稳定。
def eval_model(model):
# 预测未来 48 小时
pred_series = model.predict(n=48, num_samples=168, future_covariates=cov_val)
plt.figure(figsize=(21, 9))
# 可视化:最近 168 小时的训练数据 + 前 72 小时的验证数据
train_transformed[-168:].plot(label="train (last 7 days)")
val_transformed[:72].plot(label="val (first 3 days)")
# 预测结果及其置信区间
pred_series.plot(
label="forecast",
low_quantile=0.01,
high_quantile=0.99,
)
# 只在重叠部分计算 MAE / RMSE,这里取验证集前 48 小时
metrics_mae = mae(pred_series, val_transformed[:48])
metrics_rmse = rmse(pred_series, val_transformed[:48])
plt.title(f"MAE: {metrics_mae:.2f}, RMSE: {metrics_rmse:.2f}")
plt.legend()
return metrics_mae, metrics_rmse
mae_val, rmse_val = eval_model(model_en)
print("Validation MAE:", mae_val)
print("Validation RMSE:", rmse_val)
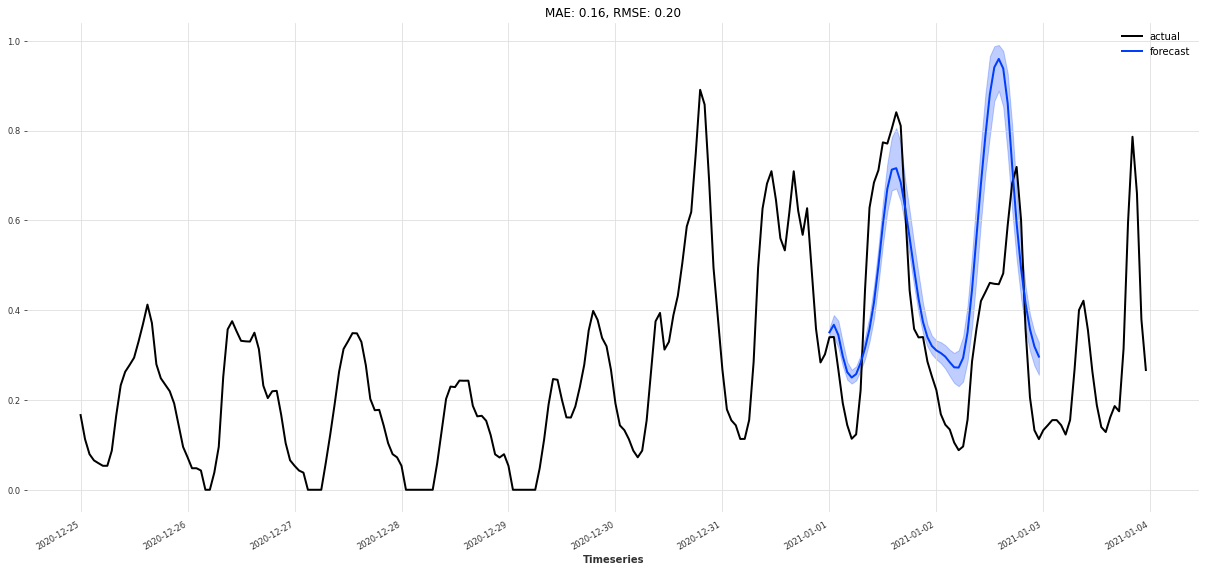
图中你能看到:
- 浅色带代表预测区间(比如 1%–99% 分位数)
- 深色线是 DeepAR 给出的预测均值
- 蓝色/橙色是历史的真实功率曲线
如果预测区间大致包住了真实值,而且均值曲线的趋势跟实测较吻合,说明模型对于这个问题是「说得过去」的;MAE / RMSE 则给出了量化指标。
保存模型以便后续复用
训练好的模型可以直接保存为文件,方便在生产环境中加载使用:
# 保存模型参数
model_en.save_model("deepar_v010.pth.tar")
后续你可以在另一个脚本中这样加载:
from darts.models import RNNModel
loaded_model = RNNModel.load_model("deepar_v010.pth.tar")
小结
这篇实战中,我们做了这样几件事:
- 使用 Darts 将风电功率数据封装为
TimeSeries对象,并按小时重采样。 - 按时间切分训练集和验证集,只在训练集上拟合标准化器。
- 构造了 年 / 月 / 日 三类时间特征作为协变量,让模型更容易捕捉长期和季节性变化。
- 使用
RNNModel + GaussianLikelihood搭建了一个 DeepAR 风格的概率预测模型,利用过去 168 小时的历史去预测未来 48 小时。