 lane4dev
lane4dev
联网检索 API 服务调研
在 RAG、Agent 等应用里,“联网检索”已经从“可选增强”变成了基础设施:
没有搜索,就很难保证答案是最新的, 搜索结果如果不够“干净”“结构化”,又会拖累 LLM 的效果和成本。
本次调研聚焦以下两个问题:
- 目前主流联网检索 API 的类型和代表产品有哪些?
- 在大模型应用场景下,各类方案的定位、优势、局限分别是什么,可用于哪些典型场景?
文档结构分为:
- 国际市场(以 Dify 集成能力为核心视角);
- 国内 AI 搜索平台;
- 关键对比维度与选型建议。
整体趋势概览
从市场形态上看,联网检索 API 大致走出两条线:
-
传统 SERP / 抓取型 API
- 典型如:Serper、SearchApi.io、Serply.io 等,它们本质是对 Google 等搜索引擎 SERP 的结构化封装。
- 优点是数据直接来自主流搜索引擎,排名逻辑接近“真实用户搜索体验”;
- 缺点是偏向 SEO / 抓取场景,对 LLM 友好程度有限(摘要、去噪、去重、长上下文聚合等需要自己做)。
-
为 LLM 设计的“AI 搜索 / Web Access API”
- 代表如 Tavily:原生为 Agent / LLM / RAG 设计,提供 Search、Extract、Map、Crawl 等能力,返回经过清洗和结构化的内容。
- 国内则出现了天工 AI 搜索、博查 Web Search API、秘塔 AI 搜索 API 等,核心卖点都是“给 AI 用的搜索引擎”。
同时,传统官方搜索 API(如 Bing Search API、Google Programmable Search JSON API 等)也在发生迁移:
Microsoft 已宣布 Bing Search API 将于 2025-08-11 退役, 引导开发者使用 Azure AI Agents 中的 “Grounding with Bing Search” 来为 LLM 提供实时 Web 数据。
Google 侧重通过 Programmable Search Engine + Custom Search JSON API 暴露官方搜索能力,按千次调用收费。
整体来看,面向 LLM 的“AI 搜索 API”正在从传统 SERP 抓取中分化出来,成为一个独立赛道。
国际联网检索 API 盘点(Dify 集成视角)
Tavily Search & Extract
定位:
明确定义为“给 AI Agents 用的 Web Access 层”,提供 Search / Extract / Map / Crawl 多种 API。
Dify 已将 Tavily 作为插件集成,可在 Chatflow / Workflow / Agent 中直接作为检索工具或数据源使用。
主要特征:
搜索结果默认做了去噪、聚合和摘要,返回 JSON 结构较适合直接喂给 LLM。
提供 Extract API,可对指定 URL 抽取正文内容,方便构建“边爬边嵌入”的知识管道。
支持通过参数控制搜索深度、结果数量、域名过滤等。
典型场景:
DeepResearch 类自动调研流程:多轮搜索 + 总结 + 生成报告。
RAG 知识管道:用 Tavily 作为数据源爬取主题网页,经过切片 & 向量化后入库。

SERP 类 API:Serper、SearchApi.io、Serply.io
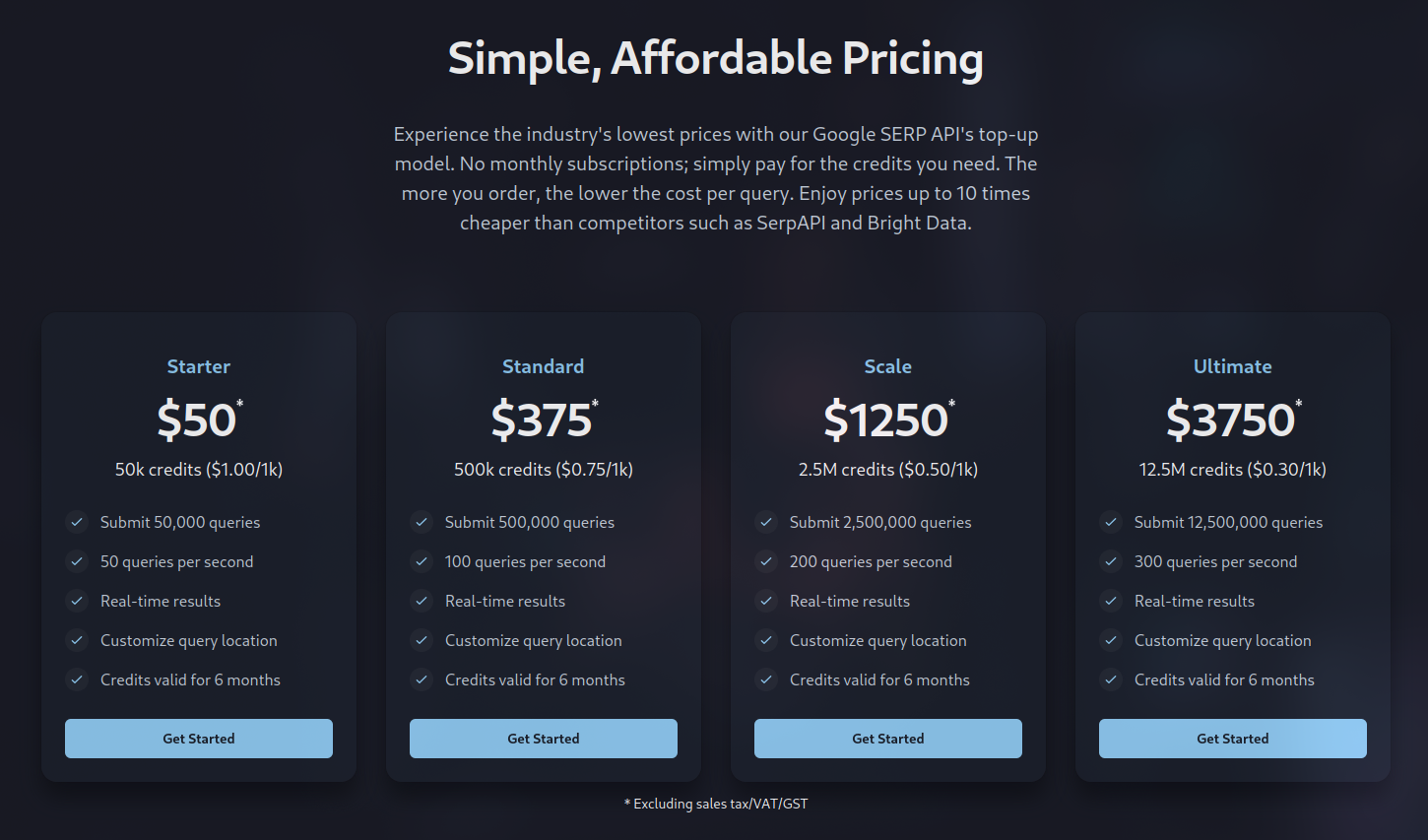
Serper.dev(Google SERP API)
标榜“最快 & 最便宜的 Google Search API”,提供 Web、图片、新闻、地图、购物、Scholar 等多种搜索类型。
价格起步低、免费额度友好,适合大规模 SERP 抓取与 SEO/监控场景。
SearchApi.io
主打“Real-time SERP API for Google Search”,支持精细的地理定向、本地化参数、SafeSearch 等。
提供 rank tracking 功能,可一次拉取较多条自然结果(例如 Rank Tracker API 支持最多 100 条)。
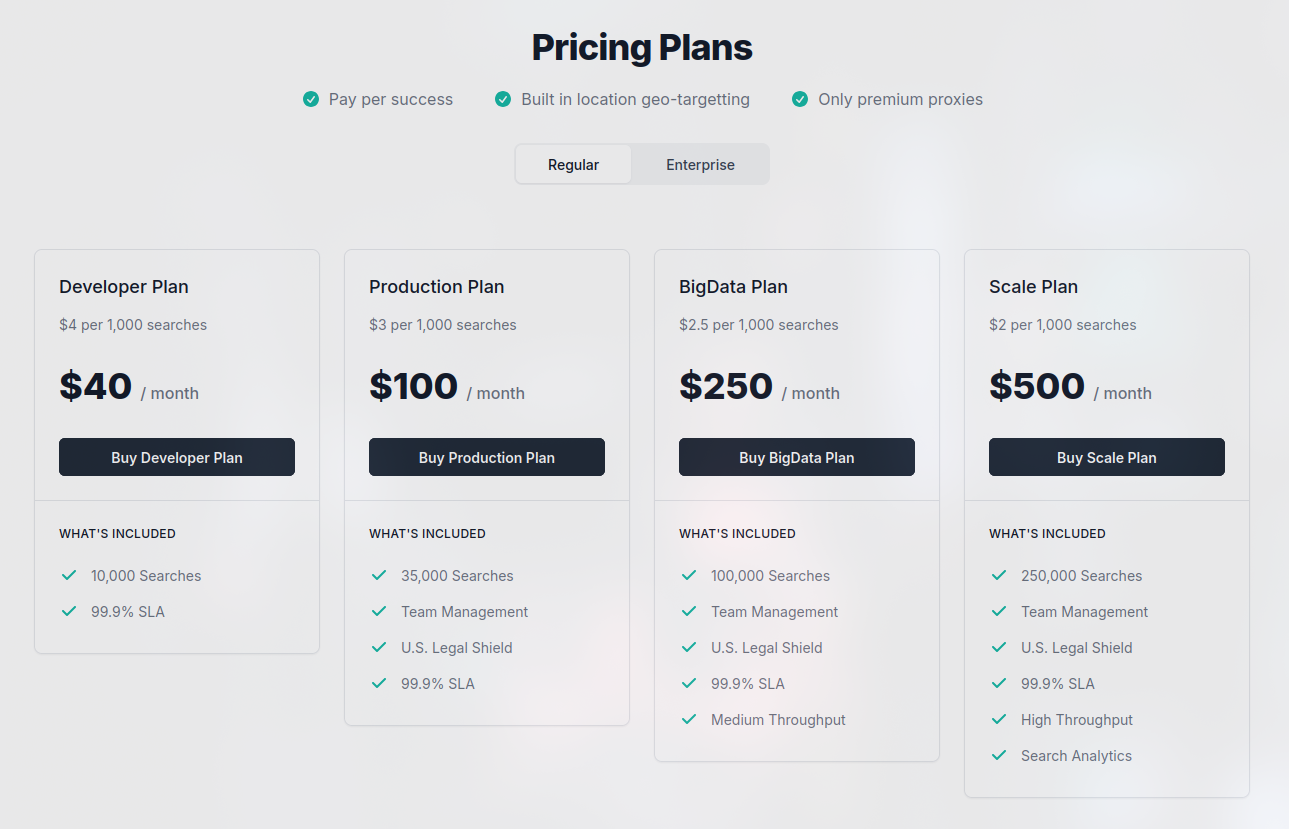
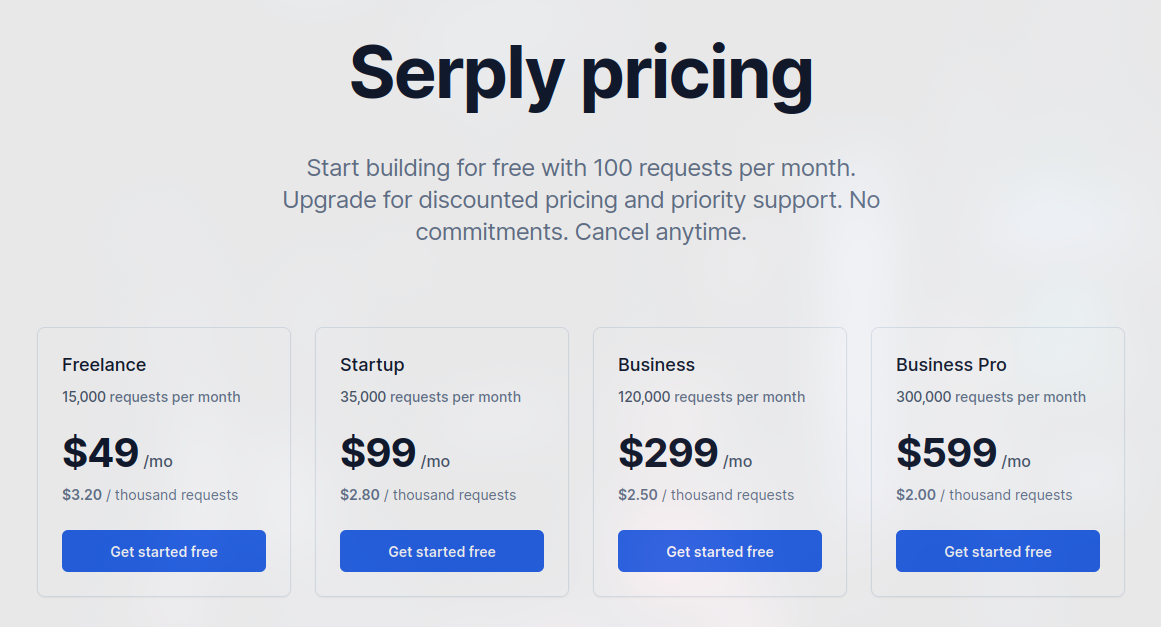
Serply.io
定位为 “Simple and fast SERP APIs designed for builders”,除了 Google SERP API,还提供 News / Image / Scholar / Video / Crawl 等纵向接口。
更偏向开发者友好的统一 SERP 服务,可按业务自由组装。
对 LLM 场景的特点:
-
优点:
原始 SERP 数据保留完整,可让 Agent 或自建 reranker 再处理;
数据贴近“真实搜索排名”,有利于做“与真实用户体验一致”的结果评估。
-
局限:
默认不会帮你做长文本摘要、内容去重和多轮整合;
结果往往是“链接 + snippet”,LLM 仍需再抓取网页正文(额外调用或自建爬虫)。
开源自建方案:SearXNG
SearXNG 是一个开源的 meta search engine,可聚合多达 200+ 搜索服务(包括 Google、Bing、DuckDuckGo 等),强调隐私友好、无用户画像。
支持自建实例并通过 API 提供结果,非常适合对隐私与合规有严格要求、希望掌控检索基础设施的团队。
适用场景:
私有化部署的大模型平台(如企业内网 Agent 平台),不希望将用户查询泄露给第三方,
灵活组合多个搜索源(如同时使用新闻源 + 代码托管源),自行控制权重与过滤策略。
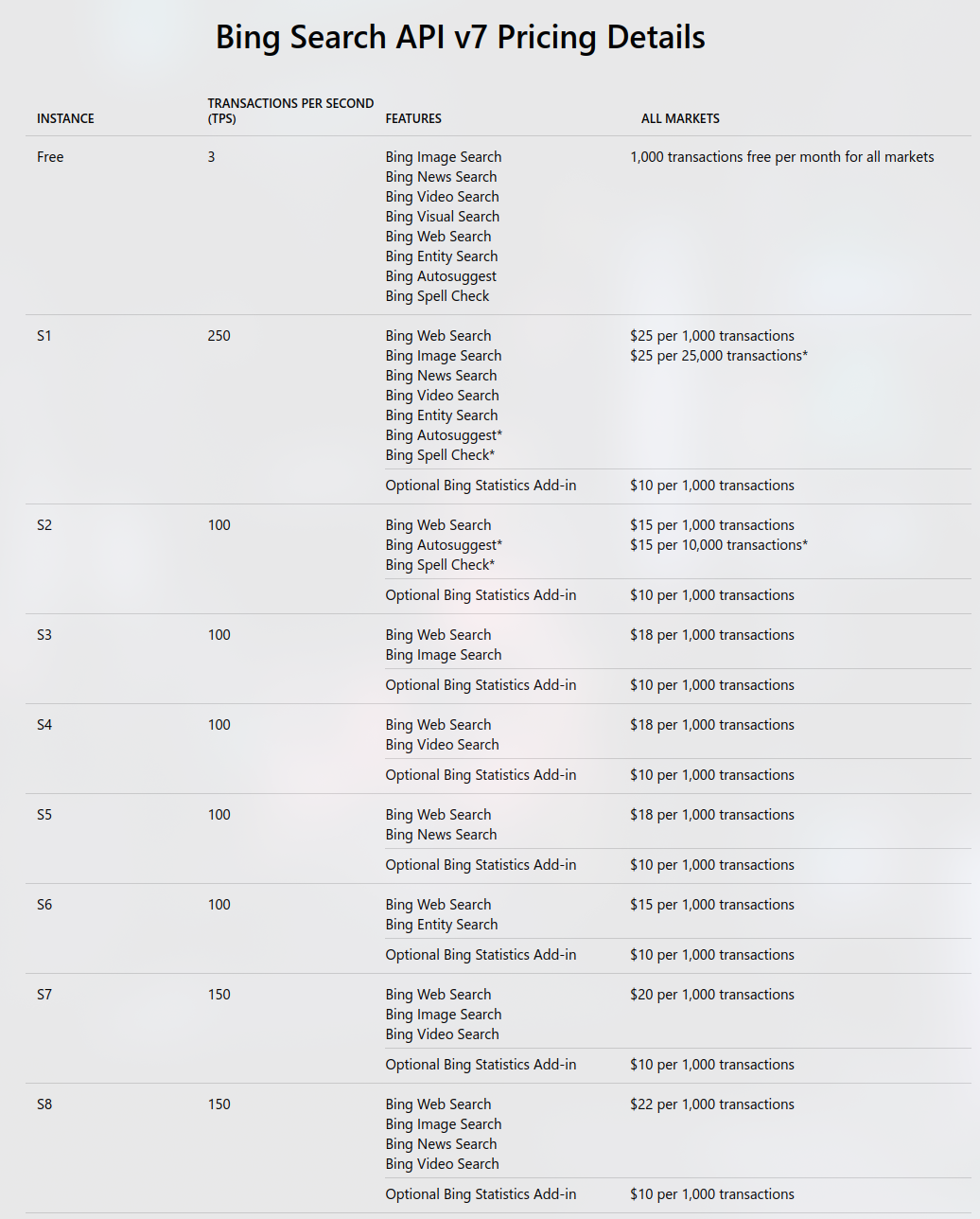
官方搜索 API
Bing
传统 Bing Search API(Bing Web/Image/News 等)将于 2025-08-11 完全退役, 微软建议迁移至 Azure AI Agents 中的 “Grounding with Bing Search”。
未来如果你使用 Azure 生态构建 Agent,可以直接通过“grounding”让模型调用 Bing 检索, 而不是单独调 Web Search API。
DuckDuckGo
官方只提供 Instant Answer API,可以获取话题摘要、分类、歧义消解等“零点击答案”;但明确说明 不是完整的搜索结果 API。
更适合做“简短事实问答”补充,而不是通用 Web 搜索。
Google Programmable Search + Custom Search JSON API
Google 的官方方案是:先通过 Programmable Search Engine 配置要搜索的站点集合,再通过 Custom Search JSON API 以 REST 方式获取搜索结果(JSON)。
JSON API 按千次查询计费(文档示例为每 1000 次约 5 美元,具体以最新定价为准),每天有调用上限。
官方 API 更适合:
- 搜索自己的网站 / 特定站群;
- 对合规和 SLA 有较高要求的企业项目。
国内联网检索 API 盘点
天工 AI 搜索 / 搜索增强模式
天工是昆仑万维推出的中文大模型和 AI 助手,平台提供多种 API,包括聊天、搜索增强模式等。
“天工 AI 搜索基础版”作为专用 API,将传统搜索引擎结果与天工大模型的总结能力结合,直接返回针对问题的结构化答案。
特点:
适合“问一题,给一篇总结”的问答型应用;
对中文内容(尤其是泛互联网知识、资讯)支持度较好;
更像一个“集成了搜索的问答 API”,而不是单纯的 SERP 抓取服务。

博查 AI Web Search API
博查定位为“给 AI 用的世界知识搜索引擎”,提供 Web Search API 与排序/Rerank API,支持自然语言搜索。
数据源覆盖近百亿网页和生态内容源(新闻、图片、视频、百科、机票酒店、学术等),日调用量已达千万级。
特点:
明确面向 AI 应用,返回结构化 JSON,支持自然语言长问句;
提供 Rerank / 排序能力,方便与自建向量库结合做“多路召回 + 语义重排”;
更接近 Tavily 的定位,是目前国内较成熟的“AI 搜索 API”。

秘塔 AI 搜索 API
秘塔 AI 搜索面向 C 端以“没有广告、直达结果”著称,支持自动生成大纲、思维导图、相关事件/人物等结构化信息。
近期推出的 API 将搜索 / 网页 / 问答 作为三个主要能力开放,可通过 cURL、Python 等多种方式调用。
特点:
API 一次调用即可获得“已总结好的答案 + 引用源”,适合用作 LLM 的前置提炼器;
更偏“AI 助手 + 搜索”的一体化形态,适合构建面向最终用户的智能问答产品。
关键对比维度
可以用下表做一个粗略的选型参考(仅为定性归类):
| 维度 | Tavily | Serper / SearchApi / Serply | SearXNG | 天工 / 博查 / 秘塔 |
|---|---|---|---|---|
| 核心定位 | AI 搜索 / Web Access | SERP 抓取 / SEO | 自建 meta 搜索 | “给 AI 的中文搜索” |
| 数据来源 | 多源聚合,偏全球 | 以 Google SERP 为主 | 可配置多搜索源 | 国内互联网为主,部分全球 |
| 返回形态 | 已清洗的摘要 + 片段 | 原始 SERP(链接 + snippet) | 原始 SERP | 问答式结果 + 引用 / 结构化摘要 |
| 对 LLM 友好度 | 高:专门为 Agent / RAG 设计 | 中:需自己做抓取 + 摘要 | 取决于自建处理链路 | 高:本身就是“AI 搜索” |
| 部署模式 | SaaS | SaaS | 自建 + 配置 | SaaS(部分支持企业版部署) |
| 隐私 / 合规 | 取决于供应商 | 同左 | 可完全自控 | 需关注数据出境与合规条款 |
选型建议(面向 Dify + 联网检索场景)
结合上面的盘点,如果目标是:在 Dify 里给 Agent / Workflow 加联网检索能力,可以大致这样规划:
-
全球通用 + 主要做“调研 / RAG”
首选:Tavily(已深度接入 Dify,使用门槛最低,结果对 LLM 友好);
如需要获取更原始的 SERP 或做 SEO / 排名监控,可增补 Serper / SearchApi.io / Serply.io。
-
对隐私 / 合规要求高,需要私有化
可考虑自建 SearXNG 实例,再在 Dify 中封装为 HTTP 工具;
上层仍可使用与 Tavily 类似的“多轮搜索 + 总结”工作流。
-
以中文内容为主,用户主要在国内
优先评估:博查 Web Search API、秘塔 搜索 API、天工 AI 搜索基础版:
- 博查:更偏AI 用搜索 + Rerank,适合做 RAG / Agent。
- 秘塔:偏面向终端问答,适合作为预摘要 + 引用源接口。
- 天工:更适合作为带搜索增强的大模型 API,而不是纯搜索底座。
-
避免过度依赖即将退役的 API
不建议在新项目中将传统 Bing Search API 作为唯一依赖,应优先考虑 Tavily / SERP API / 国内 AI 搜索方案。
小结
联网检索 API 已经从“通用搜索抓取”分化为“SERP 抓取”与“AI 搜索 / Web Access 层”两大类;
对大模型应用来说,后者(Tavily、博查、秘塔、天工等)往往能显著减少你在清洗、摘要、聚合上的工作量;
在 Dify 这类低代码平台中,可以通过插件/工具,把不同类型的搜索 API 组合进一个“多路检索 + RAG”的统一工作流里,形成自己的联网检索基座。