 lane4dev
lane4dev
从零上手 spaCy:中文 NLP 的实用入门指南
我一直觉得,做中文 NLP 很容易走两条极端,要么写一堆零散的正则和脚本,勉强把需求拼起来, 要么脑子一热,直接把问题全丢给大模型。但真到落地一个能长期跑在生产上的小系统, 比如从风电 / 光伏新闻里稳定抽出装机容量、上网电量这些指标——你会发现,光靠“大力出奇迹”其实挺难维护的。
spaCy 对我来说,就是在这两端之间找到的那条“中间道路”,它足够工程化,能舒服地接进现有代码和服务。 同时又保留了规则、传统机器学习、甚至挂上 LLM 的空间。
这篇文章想做的事很简单:从零开始,把我自己摸索 spaCy 中文工作流的过程梳理一遍, 从安装、分词、NER,到规则匹配、模型训练,再到和 RAG / 问答系统打配合。 如果你也在为“如何把中文文本处理做得既靠谱又不折腾人”发愁,希望这篇小指南能帮你少踩几些坑。
spaCy 是什么?能帮我做什么?
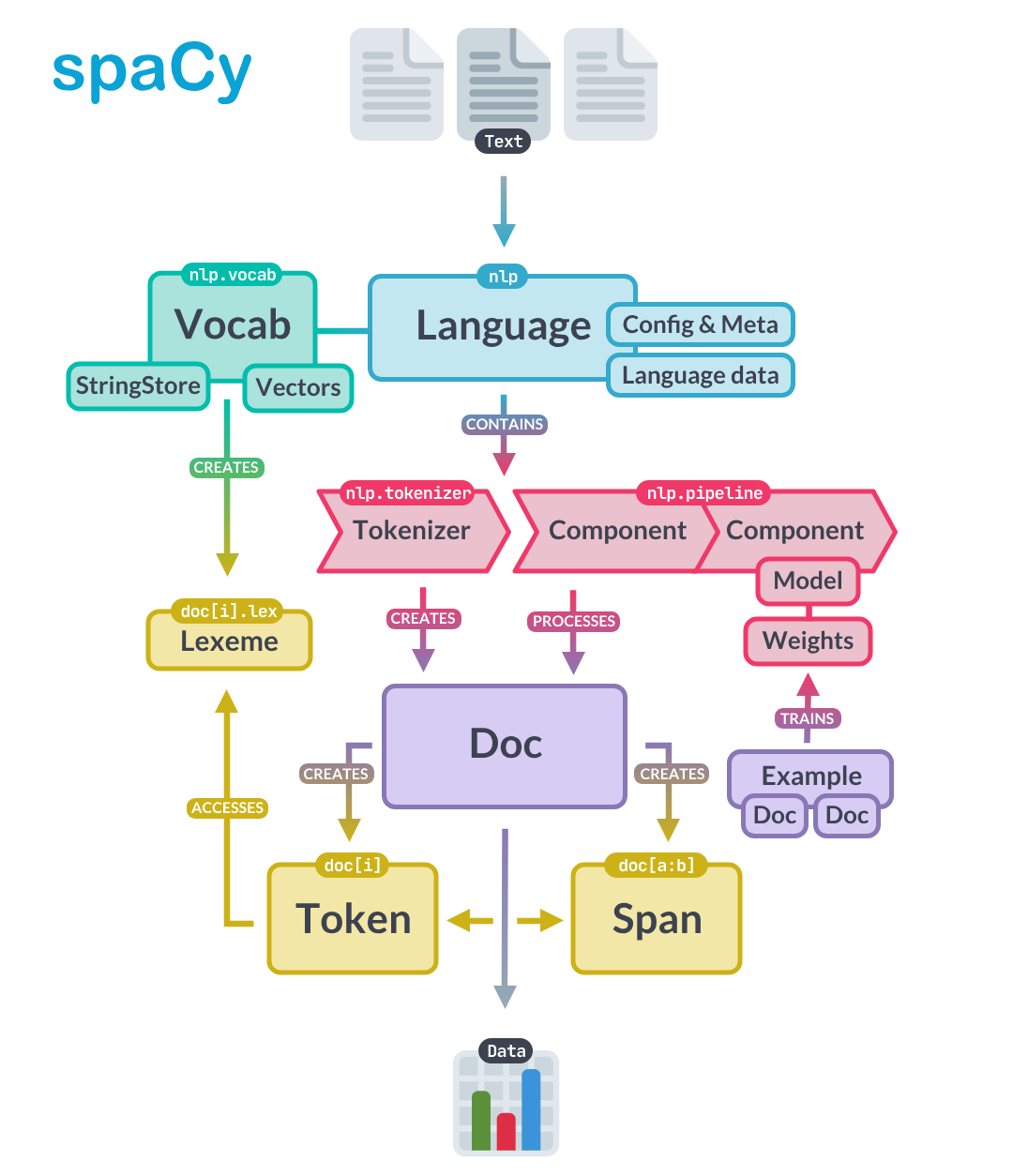
spaCy 是一个开源的 Python 自然语言处理(NLP)库,定位很明确: 给工程师用的工业级 NLP 框架。
它的特点大致可以概括为几句:
- 内置成熟的 分词、词性标注、依存句法分析、命名实体识别 等能力;
- 跑得不慢,工程化程度比较高,方便接入现有系统;
- 支持 75+ 语言,包括中文;
- 可以和 传统机器学习、深度学习,甚至 大语言模型(LLM) 配合使用。
如果你需要: 从文本中抽取结构化指标(比如,我需要从新能源新闻里抽项目规模、装机容量、上网电量等指标), 做文本相似度计算、文本分类、打标签, 为 RAG 或问答系统做更干净的结构化预处理。 那 spaCy 是一个很合适的基础工具。
准备工作
安装 spaCy
pip install spacy
❗ 建议使用虚拟环境(如 venv 或 conda)来管理依赖。
安装中文模型
spaCy 官方提供了一系列中文模型,例如:
zh_core_web_smzh_core_web_mdzh_core_web_lgzh_core_web_trf(基于 Transformer 的大模型)
一般来说:
- 快速尝鲜:
zh_core_web_sm - 精度更高 / 生产环境:优先考虑
md/lg/trf系列
安装示例(以 zh_core_web_sm 为例):
python -m spacy download zh_core_web_sm
使用时加载模型:
import spacy
nlp = spacy.load("zh_core_web_sm")
doc = nlp("12月29日上午,华能贵港七星岭风电项目开工仪式在覃塘区东龙镇举行。")
spaCy 的基础概念
💡 接下来所有例子,统一用下面这段风电新闻作为示例文本,方便你对比感受不同功能的差异。
12月29日上午,华能贵港七星岭风电项目开工仪式在覃塘区东龙镇举行,标志着贵港市第一个风电项目正式开工建设。
▲现场奠基图▲项目开工仪式现场图据悉,华能贵港七星岭风电项目总投资5.9亿元,本期工程核准容量 60MW,
采用 27台 单机容量 2兆瓦 及以上的风机发电机组,预计年上网电量为 15668万千瓦时,年平均利用小时为 2611小时,
建成投产后每年将上缴地方税收 1200万元。▲效果图▲效果图华能贵港七星岭风电项目的开工建设,
将对我市壮大绿色环保经济起到积极的作用。
Tokenization
Tokenization(分词 / 切词) 是 spaCy 的入口: 把一整段文本拆成「词、标点符号、数字」等基本单元,后续的词性标注、实体识别都基于它。
doc = nlp(article["body"])
for token in doc:
print(token.text)
示例输出(部分):
12月
29日
上午
,
华能
贵港
七星
岭风电
项目
开工
仪式
在
覃塘区
东龙镇
举行
,
...
这里能看到:
- spaCy 已经把 日期、地名、项目名称 这些元素拆成了一个个 token;
- 后面我们可以基于这些 token 去做规则匹配和实体识别。
词性标注(POS Tagging)
POS Tagging(词性标注) 会给每个 token 打上词性和句法信息,比如:
这个词是名词、动词、数词、专有名词…… 这个词和其他词之间的语法依赖关系是什么(主语、宾语等)。
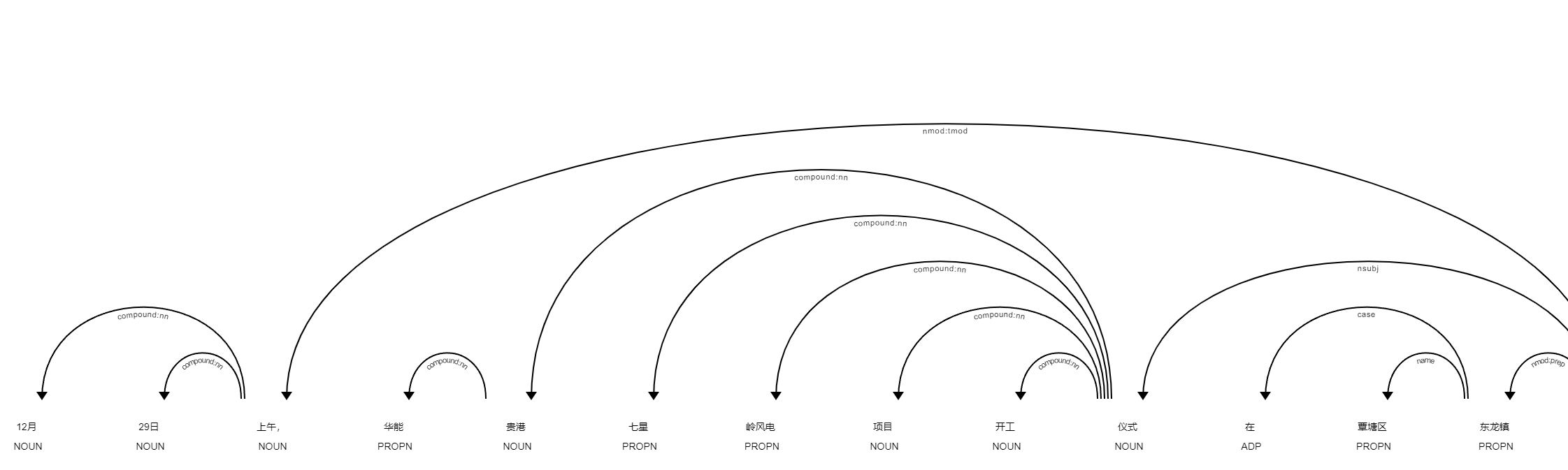
简化示例(非真实输出,仅示意):
12月 NOUN compound:nn
29日 NOUN compound:nn
上午 NOUN nmod:tmod
华能 PROPN compound:nn
贵港 NOUN compound:nn
七星 PROPN compound:nn
岭风电 PROPN compound:nn
项目 NOUN compound:nn
...
举行 VERB ROOT
这层信息在后面两类场景特别有用:
- 规则匹配时,做更“聪明”的筛选(比如只匹配动词后面的数值)
- 做复杂语法规则的抽取(用 Dependency Matcher)
命名实体识别(NER)
Named Entity Recognition(命名实体识别) 的目标是: 从文本中自动识别出 人名、地名、组织、时间、金额等像名词又比普通名词重要的东西。

在风电项目的场景里,我们更关心的可能是:
- 项目名称、项目类型;
- 总投资、装机容量;
- 年上网电量、平均利用小时数;
- 风机数量、单机容量等。
这种行业特化的实体往往需要你自己通过 规则 + 训练 来定制,后面会专门讲。
向量和相似度
spaCy 也支持 词向量 / 文档向量 和 相似度计算。 你可以用它来:
- 粗略比较两段文本“是不是一个意思”;
- 在索引前做预筛选,或者给搜索结果排序。
示例代码(使用英文 en_core_web_md 模型):
import spacy
nlp = spacy.load("en_core_web_md")
doc1 = nlp("I like salty fries and hamburgers.")
doc2 = nlp("Fast food tastes very good.")
print(doc1, "<->", doc2, doc1.similarity(doc2))
中文场景下,你可以换成支持向量的中文模型,或自己训练 / 接入外部向量。
句子边界识别
很多时候,我们更希望“按句子”为单位来分析,比如:
- 找到包含特定实体的句子;
- 把长文本切成一段段“比较完整”的句子,方便后续分类或 QA。
for sent in nlp(article["body"]).sents:
print(sent.text)

配合 NER 使用,你可以做到: 先找到所有装机容量实体,再把它们所在的句子取出来,结合上下文进行二次判断。
基于规则的匹配
spaCy 的一个工程向非常强的功能就是 Rule-based Matching(基于规则的匹配)。 当你大致知道文本长什么样时,规则往往比纯模型更简单更稳定。
Token-based Matcher
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
matcher.add("项目规模/装机容量", [
[{"TEXT": {"REGEX": r"(\d+\.?\d*\s?(MW|兆瓦))"}}],
])
matcher.add("上网电量/发电量", [
[{"TEXT": {"REGEX": r"(\d+\.?\d*\s?(GWh|千瓦时|万kW·h))"}}],
])
doc = nlp(article["body"])
matches = matcher(doc)
for match_id, start, end in matches:
string_id = nlp.vocab.strings[match_id]
span = doc[start:end]
print(match_id, string_id, start, end, span.text)
这里我们用简单的正则匹配了:
60MW/2兆瓦之类的 装机容量;15668万千瓦时等 上网电量 / 发电量。
对于“指标提取”来说,这已经是一个不错的起点。
EntityRuler
如果你希望这些匹配结果直接变成 doc.ents 里的实体,可以用 EntityRuler:
from spacy.lang.zh import Chinese
nlp = Chinese()
cfg = {"segmenter": "pkuseg"}
nlp = Chinese.from_config({"nlp": {"tokenizer": cfg}})
nlp.tokenizer.initialize(pkuseg_model="news")
text = "...上面那段风电项目新闻..."
doc = nlp(text)
ruler = nlp.add_pipe("entity_ruler")
patterns = [
{"label": "单机容量", "pattern": [{"TEXT": "单机"}, {"TEXT": "容量"}, {"TEXT": {"REGEX": r"(\d+\.?\d*\s?(MW|兆瓦))"}}]},
{"label": "项目规模/装机容量", "pattern": [{"TEXT": {"REGEX": r"(\d+\.?\d*\s?(MW|兆瓦))"}}]},
{"label": "利用小时数", "pattern": [{"TEXT": "利用小时"}, {"ORTH": "为"}, {"TEXT": {"REGEX": r"(\d+\.?\d*\s?(小时))"}}]},
{"label": "风机数量", "pattern": [{"TEXT": {"REGEX": r"(\d+\s?(?:台|套))"}}]},
]
ruler.add_patterns(patterns)
doc = nlp(text)
# 例如用 displacy 在 Notebook 中高亮实体
from spacy import displacy
displacy.render(doc, style="ent", jupyter=True)

这一步可以看成是让规则匹配结果,进入 NER 的生态圈。
SpanRuler
有时候你不想把所有匹配都变成 doc.ents,而是希望单独存放,比如 doc.spans["ruler"]。
SpanRuler 就是为这种场景设计的。
ruler = nlp.add_pipe("span_ruler")
patterns = [
{"label": "项目规模/装机容量", "pattern": [{"TEXT": {"REGEX": r"(\d+\.?\d*\s?(MW|兆瓦))"}}]},
{"label": "上网电量/发电量", "pattern": [{"TEXT": {"REGEX": r"(\d+\.?\d*\s?(GWh|千瓦时|万kW·h))"}}]},
]
ruler.add_patterns(patterns)
doc = nlp(article["body"])
print([(span.text, span.label_) for span in doc.spans["ruler"]])
简单理解:
Entity更偏语义上的命名实体;Span更像你想额外标记出来的一段文本。
其它规则工具一览
你完全可以根据需求自由组合:
- PhraseMatcher:对一堆固定短语做高速匹配,适合关键词列表;
- DependencyMatcher:基于依存句法树,描述更复杂的语法模式;
- Combining models and rules:模型负责“泛化能力”,规则负责“刚性约束”,两者相得益彰。
传统机器学习
当规则已经有点吃力,希望模型具备更多“举一反三”的能力时,就需要走上 模型训练 这条路。

典型流程大概如下:
准备训练数据
TRAIN_DATA = [
("The F15 aircraft uses a lot of fuel", {"entities": [(4, 7, "aircraft")]}),
("did you see the F16 landing?", {"entities": [(16, 19, "aircraft")]}),
# ...
("is the F35 a waste of money", {"entities": [(7, 10, "aircraft")]}),
]
中文场景下,把 "aircraft" 替换成你关心的标签,比如 "项目规模/装机容量", "风机数量" 等。
转换为 .spacy 格式
通过官方工具把原始标注数据转换成 spaCy 自己的二进制格式。
创建并填充配置文件
先初始化一个基础配置:
python -m spacy init fill-config base_config.cfg config.cfg

你可以在 config.cfg 里指定:
- 使用哪个语言;
- pipeline 里有哪些组件(
tok2vec,ner等); - 训练超参数等。
启动训练
python -m spacy train config.cfg \
--output ./output \
--paths.train ./train.spacy \
--paths.dev ./dev.spacy
训练完成后,会在 ./output 目录下生成一个可加载的模型,你可以像加载官方模型那样用它:
nlp = spacy.load("./output/model-best")
doc = nlp(article["body"])
结合大语言模型:spacy-llm 的玩法
如果你已经在用 ChatGPT / Llama 等 LLM,spaCy 提供了 spacy-llm 组件, 可以把 LLM 当成 spaCy pipeline 中的一个“黑盒组件”,做 NER、分类等任务。
基本配置示例
[nlp]
lang = "en"
pipeline = ["llm"]
[components]
[components.llm]
factory = "llm"
[components.llm.task]
@llm_tasks = "spacy.NER.v3"
labels = ["单机容量", "风机数量", "装机容量", "年上网电量"]
[components.llm.model]
@llm_models = "spacy.GPT-3-5.v1"
config = {"temperature": 0.3}
使用方式示例
from spacy_llm.util import assemble
from dotenv import load_dotenv
load_dotenv() # 加载 API Key 等配置
nlp = assemble("config.cfg")
doc = nlp(
"12月29日上午,华能贵港七星岭风电项目开工仪式在覃塘区东龙镇举行..."
)
for ent in doc.ents:
print(ent.text, ent.label_)
输出示例(理想情况):
27台 风机数量
单机容量 2兆瓦 单机容量
60MW 装机容量
15668万千瓦时 年上网电量
这类方案的好处是: 用 llm 来干理解复杂语义的重活, 用 spaCy 做数据流转、结构化、与已有 pipeline 的集成。
Workflow 与工程实践:跑通一个从“文本到指标”的流程

官方也提供了一些项目模板和工具(如 explosion/projects、weasel),方便你定义端到端的 NLP 流程。
在“风电 / 光伏指标提取”的典型场景中,可以设计这样一条链路:
- 原始文本清洗:去掉 HTML、特殊符号等;
- spaCy 预处理:分词、句子切分、基本 NER;
- 规则匹配 + EntityRuler / SpanRuler:抽取装机容量、上网电量、风机数量、利用小时数等;
- LLM / 自训练 NER 校正:对规则结果进行语境修正(例如“这里的 60MW 是项目规模还是风机单机容量?”);
- 指标结构化输出:生成统一的 JSON / 表格,进入后续数据存储或 RAG 过程。
spaCy 的几个典型用法
指标提取与数据清洗
- NER:识别项目名、公司名、金额、装机容量等;
- Similarity:项目名称与项目位置的模糊匹配;
- Text Classification:为文档打“项目阶段”“能源类型”等标签;
-
Document ranking / classification:
- 给新闻质量打分,过滤掉噪声;
- 按“是否为正式公告”之类的维度分类。
与规则 & QA 结合
- 先通过规则 / NER 找到候选实体;
- 再看实体所在句子,用关键字 + 语境做进一步判断;
- 或者把相关句子送入 QA 模型,做类似 RAG 的问答抽取:
QA_input = {
"question": "Who controls Deir Hafer and Al-Bab?",
"context": sent.text,
}
res = hugg(QA_input)
(示例是英文战地新闻,同样的套路可以用在光伏 / 风电项目文本里。)
服务于 RAG 与 Prompt 处理
在 RAG 系统中,spaCy 可以用来:
- 对长文本做更智能的切分(按句子 / 段落);
- 抽取关键词,用于构建索引或 Prompt;
- 配合 LlamaIndex 等框架优化 Node Parser / Text Splitter 的效果。
结语
如果把整条 NLP 工程链路比作一条“生产线”, spaCy 更像是那套 可靠、标准化、可组合的流水线设备:
一端接入原始新闻、公告、报告, 中间完成分词、标注、实体识别、规则抽取、模型推理, 另一端吐出干净、结构化的指标、标签, 供风电 / 光伏评估系统、RAG 系统或 Dashboard 使用。
在入门阶段,可以先把这几块弄熟:
- 分词、POS、NER、句子分割
- Matcher / EntityRuler / SpanRuler 的规则抽取
- 简单的 模型训练 或 spacy-llm 集成
等到这些基础打稳,再去扩展 Workflow、和现有业务系统深度整合,就会顺畅很多。