 lane4dev
lane4dev
AI Coding 技术分享:工具、Prompt 与协作流程全解析
这篇文章基于我的一份讲座 PPT 材料整理而来。
原始内容最初是我为一次关于 AI Coding 的分享准备的讲稿与提纲,因此整体结构天然带有一种从概念到工具、从方法到落地的演讲节奏。 为了让它更适合阅读,我在整理成文的过程中,对部分内容顺序、段落衔接和表达方式做了重新组织, 也补充了一些在现场分享里来不及展开、但我认为很关键的实践经验与个人思考。
过去一年的时间,互联网上关于 AI Coding 的讨论,几乎有点像一种新型宗教。 一派人情绪高昂,仿佛不久之后所有程序员都会被大语言模型替代; 另一派人则不屑一顾,觉得这不过是一个会吐样板代码的高级补全器,热闹一阵就会过去。
我对这两种说法都不太认同。
因为真正把 AI 放进日常开发流程里之后,你会很快发现:它既没有宣传里那么玄,也没有某些人说得那么废。 它像一把动力很强、扭矩也很大的电动工具。你拿它去拧螺丝,当然会比手拧快; 但如果你根本不知道这颗螺丝该不该拧、应该拧到哪里、拧紧之后会不会把整块板子带裂,那工具越猛,不良后果往往也越严重。
所以,这篇文章不打算讨论AI 会不会取代程序员这种聊起来很上头、但聊完又很难落地的话题。 我更想认真的讲清楚一件事:当 AI 把实现这件事加速之后,软件开发真正重要的部分,到底变成了什么?
如果把这件事说得再直白一点,其实就是一句话:
AI Coding 不是更快地写代码,而是更认真地写需求、更明确地写边界、更可验证地写验收。
如果你已经用过 Copilot、Cursor、Cline、ChatGPT、Claude 这一类工具,那么这篇文章不是教你如何第一次打开和使用 AI 工具。 它更像是在问:当这些工具都已经摆在桌上之后,你究竟该怎么建立一套不容易翻车、还能持续复用的工作方式?
AI Coding 不是一个工具,而是一种新的工作方式
很多人一提到 AI Coding,第一反应还是工具名:Copilot、Cursor、Cline、Claude Code、Gemini CLI …… 仿佛只要选对工具,效率问题就解决了。
但真正在项目里用久了你会发现,工具当然重要,可工具从来不是最核心的部分。真正发生变化的,是你和软件之间的分工关系。
在传统的软件开发里,我们通常默认这样一条链路:人先想清楚需求,再把需求翻译成代码,最后让机器去执行。 程序员承担的是思考和翻译的双重任务。你既要理解问题,也要亲手把问题压缩成一行行计算机能执行的语法。
而 AI 加入之后,事情开始松动了。
你不再必须把每一个细节都亲手敲成代码。你可以先用自然语言描述意图、限制、上下文、验收标准,再让模型去生成一个候选实现。 也就是说,原来由你手工完成的那一段从想法到实现细节的转换工作,现在有一部分可以交给模型。
这听起来像只是多了个中间人,但它带来的变化其实不小。
因为当实现细节被部分外包之后,你的工作重心就会开始上移。你不得不更频繁地面对下面这些问题:
- 我真正想解决的问题到底是什么?
- 这个需求的边界在哪里?
- 什么算完成,什么不算?
- 哪些地方允许模型自由发挥,哪些地方绝对不能碰?
- 我怎么确认它写出来的东西不是看起来对,而是真的对?
这时候你会发现,AI Coding 的关键能力,慢慢从会不会写代码,转向了会不会定义问题、表达约束、验证结果。
吴恩达教授在 Stanford CS230 - Autumn 2025 - Lecture 9: Career Advice in AI 授课过程中, 用图片更生动形象的展示了软件开发流程中的新瓶颈。
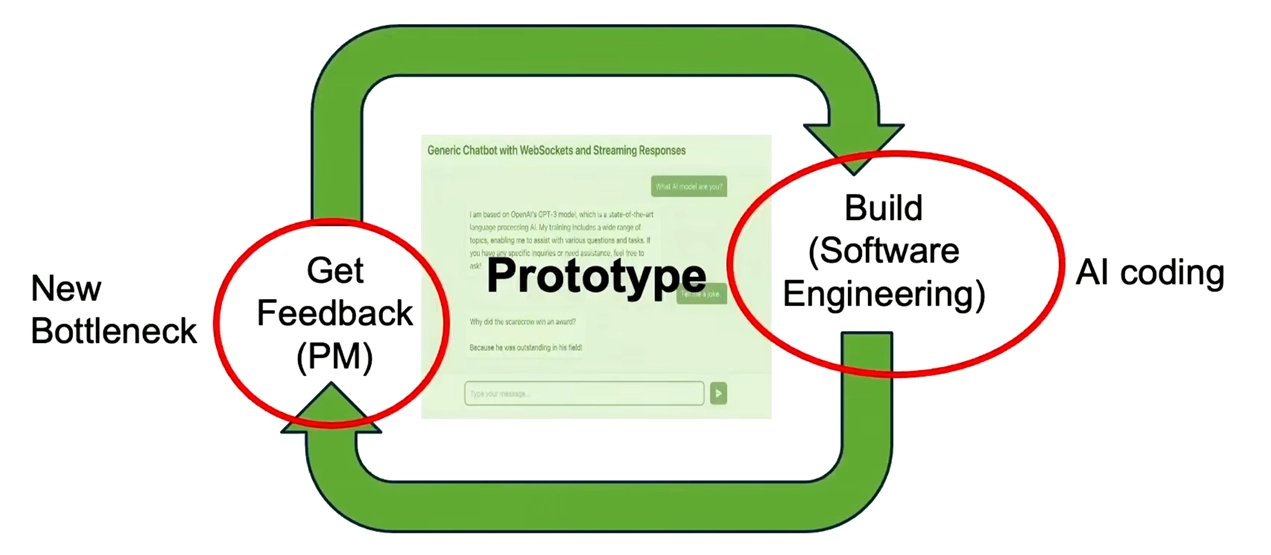
这也是我很想反复强调的一点:AI Coding 不是会用工具这么简单,它是一套从探索到交付的工作方式。 你当然可以把它当补全器用,把它当聊天机器人用,把它当一个会跑命令、会改文件、会写测试的代理用。 但无论你怎么用,最后都绕不开一个核心事实:
模型擅长实现,人必须负责定义意图。
如果这件事没想清楚,AI 再强,也很容易沦为一个把错误更快放大的加速器。
从写代码到写需求
我越来越觉得,AI 时代最容易被忽略的一件事,是很多人仍然用旧时代的写代码观在理解新时代的交付。
大家嘴上都在谈 AI,实际工作方式却还停留在过去:需求模糊、验收模糊、边界模糊,然后把一段含糊的描述扔给模型,期待它自动长出一个完美结果。 结果当然大概率不完美。于是人开始抱怨模型笨、工具不稳定、上下文太短、输出有幻觉。
这些抱怨不能说没有道理,但很多时候,它们并没有击中真正的问题。
真正的问题往往是:我们自己就没有把事情说清楚。
在没有 AI 的时候,这个问题还没有那么显眼。因为程序员需要自己写实现,写着写着总会逼自己补足空白: 这里参数到底是什么?那里异常怎么处理?这个接口到底兼容旧版本吗?这个逻辑改了会不会影响下游?
换句话说,很多模糊并不是在需求阶段被解决的,而是在编码阶段被迫解决的。
可一旦你把实现工作交给 AI,模糊就不能再拖到后面了。因为模型不是你脑内想法的读心器。 你不说,它就只能猜;你说得不完整,它就会用训练数据里最常见的套路把空白补齐; 你没有给出验收标准,它就会默认看起来差不多也算完成。
这就是为什么我会说:AI Coding 不是关于写代码的,而是关于写需求的。
这里的需求,不是那种开会时一拍脑门说出来的抽象愿景。这里说的需求,更接近一种可执行的规格说明: 你得说清楚目标、范围、边界、输入、输出、风险、验证方式,以及达到怎样的程度算是完成。
或许这听上去像在增加前置工作量。表面上看确实如此。你以前也许只需要写一句帮我重构一下这段代码,现在却要补上一堆说明: 不能改接口行为、必须通过哪些测试、风格要遵守什么原则、输出格式是什么、你希望它先给摘要还是直接给代码。
可问题在于,这些信息本来就不是新增的工作,而是原本就该存在、只是过去被个人经验临时兜住了的工作。 AI 的出现,只是把这些隐性劳动暴露出来了。
从这个意义上说,AI 并不是在替代思考,它更像是在逼你把原来只存在于脑子里的判断标准,变成显式可传达、可复用、可验证的东西。
这反而是一件好事,也是一个优秀的软件工程师应该具备的能力。
这一点,我在 Programming as theory building 读后感 一篇文章中有说明。
Vibe Coding: The Good, The Bad, and The Ugly
过去一两年,Vibe Coding 这个词已经被说得有点泛滥了。很多人只要用了 AI 写代码,就说自己在 Vibe Coding。
严格一点讲,这种说法并不准确。
Vibe Coding 之所以值得被单独拿出来讨论,不是因为它等于AI 辅助写代码,而是因为它代表了一个更极端、更前沿、也更容易让人上头的工作模式: 人负责表达高层意图,模型负责生成具体实现,而人类对代码细节的关注度显著降低。
简单说,就是先跟着感觉走,先把东西搞出来再说。
这个模式为什么诱人?因为它真的很快。
你有一个点子,一个页面,一条业务流程,一个想验证的最小原型。不必先搭骨架、建目录、写样板、配路由、造假数据、补 README。 你可以直接对着模型说:我要一个什么样的东西,它要解决什么问题,有哪些基本交互,然后在很短时间里得到一个能演示、能点、能看、能拿给别人试用的东西。
对于很多过去需要两三天、甚至一两周才能摸到形状的想法来说,这种压缩是很惊人的。
所以 Vibe Coding 真正重要的地方,不是模型能不能替你敲代码,而是它让想法变成原型的门槛和时间都下降了。 原来你得先投入很多实现成本,才能知道一个方向值不值得试。现在你可以先低成本把轮廓做出来,再去拿反馈。
从产品角度看,这个变化非常大。因为软件开发里最贵的事情,很多时候不是写代码,而是写了很多代码之后,才发现方向根本不对。
Vibe Coding 的价值,恰恰在于提前暴露这个问题。
但问题也就在这里。因为先做出来再说是很爽,可先做出来并不等于做对了,更不等于可交付, 完全依靠这种开发方式,你大概率会做出一堆看上去有点用处的玩具。
大模型很擅长生产一些看上去很对的东西,尤其是当你试图用它生成代码的时候。
生产的这类代码最大的问题不是立刻报错,而是它往往会给团队制造一种我们已经进展很多了的幻觉。 页面有了,接口也通了,日志也没报错,演示甚至还挺顺。可一旦你开始认真检查边界条件、异常路径、性能、兼容性、安全性、后续维护成本, 就会发现很多地方只是被一层漂亮的壳子盖住了。
这就是我特别想提醒的一点:Vibe Coding 的核心门槛,不是会不会写 Prompt,而是有没有足够的判断力。
这里的判断力,某种意义上就是品味。不光是审美意义上的 品味,而是工程上的 品味: 你能不能分辨一段代码只是能跑,还是值得留下;你能不能判断这个实现是在解决问题,还是在制造以后要还的债;你能不能看穿假进展。
如果一个团队缺少这种判断力,那 Vibe Coding 不是捷径,而是一条高速滑向技术债的下坡路。
所以我更喜欢把它看成一个光谱,而不是一个标签。
光谱的一端,是快但不管:只要能跑就继续推进,很少读 diff,不太在意实现细节,出了问题再说。 另一端,是快且负责:同样追求快速原型,但每一步都绑定最小验证、明确边界、保留回滚能力、 逐渐把临时产物收束成真正能维护的工程资产。
真正值得追求的,不是会不会 Vibe Coding,而是能不能把团队从光谱的左边推向右边。
Vibe Coding 改变了什么
如果只是把 Vibe Coding 当成一个酷词,那它的意义其实很有限。 真正值得重视它,是因为它背后反映出来的,不只是一个新术语,而是软件开发瓶颈的迁移。
过去大家默认软件开发的瓶颈是实现。需求有了,文档差不多了, 接下来就看开发要多久、联调要多久、测试要多久。整个节奏主要受制于把想法变成东西这一步。
AI 让这一步明显变快了。
哪怕你不采用最激进的工作方式,只把 AI 用在脚手架生成、样板代码、接口封装、单测草稿、文档整理、重构建议这些地方, 整体实现速度也会被拉起来。更不要说在一些原型验证、前端页面、后台管理系统、数据处理脚本这类场景里,速度变化会更加直接。
于是软件开发里原来不那么显眼的几个环节,开始被推到前台:
第一,是需求定义。
以前需求模糊一点,还可以边写边补;现在实现太快,需求不清楚就会更快地产生大量返工。
第二,是验收验证。
以前测试写得慢,大家还能互相体谅;现在模型两分钟给你改了五个文件、补了八个测试、顺手还跑了一遍命令,如果没有明确的验证标准,你根本不知道它到底修好了什么,又悄悄破坏了什么。
第三,是反馈回路。
原型出来更快了,意味着获得反馈这件事反而成了新的瓶颈。你内部确认慢、用户访谈慢、产品决策慢、上线观察慢,AI 在实现端带来的加速,最后就会被前后游的迟缓全部吃掉。
所以我很认同吴恩达教授的判断:速度红利是真实存在的,但速度会把压力推向两件事——把需求说清楚,以及更快地验证。
这也是为什么 AI 时代程序员的角色其实是在上移的。不是说你不需要懂代码了,恰恰相反,你得更懂。只是你不再只是在写,你更多是在做这些事:
- 决定什么值得做;
- 判断怎么做更稳;
- 把边界和风险提前暴露;
- 设计验收口径;
- 组织协作流程;
- 为结果负责。
如果说过去的工程师更像实现者,那现在很多时候,你更像产品 + 架构 + 质量负责人的混合体。你需要的,不只是敲代码的手速,而是把不确定性前置处理掉的能力。
这听上去似乎更累了。某种程度上也确实如此。AI 没有让软件开发突然变成一件毫不费力的事情,它只是把累的位置换了一下。
但这个变化也很有价值,因为它逼着团队去直面一个常年被忽略的问题:我们到底是在高效写代码,还是在高效交付价值?
这两者,差得其实很远。
AI 在不同场景下的最佳打开方式
很多关于 AI Coding 的讨论,最容易犯的一个错误,就是把所有项目当成同一种项目来谈。 可现实里,新项目和老项目的 AI 用法,根本不是一个难度级别。
新项目:最适合用 AI 去抢原型速度
新项目最适合 AI 发挥的地方,是更快拿到一个可验证结果。
因为新项目还没有沉重的历史包袱,没有一堆隐含约定,也没有复杂的兼容性问题。 这个阶段最重要的,通常不是把每一处细节都做到完美,而是尽快把核心链路搭出来,看看这个方向到底行不行。
所以对于新项目,我推荐的顺序是这样的:
- 先把任务说明写清楚,再让 AI 生成代码。
- 生成项目骨架,再逐步补细节。
- 每次只推进一个小模块,并且每一步都可验证。
注意,这里的写清楚任务说明,不是写一段豪言壮语式的愿景,而是至少回答下面这些问题:
- 这个项目这次要做什么,不做什么?
- 核心页面、核心接口、核心数据结构是什么?
- 最小可演示路径是什么?
- 什么叫可以验收?
一旦这些东西写清楚,AI 在新项目里会很有用。它特别适合先把目录结构、路由骨架、组件框架、Mock 数据、占位实现、README 这些重复劳动铺出来。 你可以很快得到一个能跑起来的雏形,然后再把时间花在真正需要人判断的地方:需求取舍、交互细节、边界处理、后续演化方向。
但即便是新项目,我也不建议一口气让 AI 改太多。因为新项目虽然包袱轻,却也最容易被快速成功的幻觉带偏。 你很容易连续让它生成很多模块,表面上进展飞快,实际上每一层都还没验稳。最后一旦某个基础决策错了,返工就会连锁发生。
所以新项目最好的节奏不是大爆发,而是小步快跑:每次只改一块,每次都能运行、能演示、能回滚。
老项目:使用 AI 的关键不是写,而是别乱改
老项目正好相反。老项目的主要问题从来不是不会生成代码,而是上下文太复杂,任何改动都可能牵一发动全身。
很多人把 AI 用在老项目上翻车,不是因为模型太弱,而是因为他们默认模型 懂他们的代码库。 实际上,模型不懂。它拿到的永远只是你给它的局部上下文,加上一些通用模式。只要你提供的信息不够,它就会猜。而老项目最怕的,恰恰就是猜。
所以老项目接入 AI 之前,我觉得最关键的一件事不是马上让它写代码,而是先补齐可用上下文。至少包括:
- 运行手册:项目怎么启动,关键配置在哪,常用命令是什么;
- 关键链路说明:入口在哪,主要调用路径怎么走,依赖边界在哪里;
- 变更边界:哪些模块可以碰,哪些需要人工确认,哪些绝对不要动。
这些东西过去或许很多团队其实都缺。没有 AI 的时候,大家靠老同事口口相传,靠出问题时临场补锅,也勉强能转。 可 AI 一来,这种隐性知识就会立刻暴露成效率瓶颈。
此外,老项目一定要把验证前置。至少要有最小测试基线、CI、格式化、静态检查、隔离环境。 你不一定一步到位做到完美自动化,但必须先有一个最小的防线。否则你每让 AI 改一次老代码,心里都会像拆盲盒。
处理老项目场景,我认同 最小改动策略:
- 每个 PR 必须写清动机、影响面、验证步骤;
- 小 PR、小 diff;
- 明确哪些地方只允许局部修改;
- 强调 review 能力;
- 要求团队仍然具备读代码和定位问题的能力。
一句话总结就是:新项目里 AI 的价值主要是更快出雏形,老项目里 AI 的价值主要是在可控范围内做可验证的小增量。
把这两种项目混着用,基本就容易出事。
为什么 AI 总是看起来对、跑起来错
很多人第一次认真用 AI 写代码之后,都会有一种共同挫败感:演示视频里别人一句话生成的效果特别惊艳,轮到自己,不管怎么写,总觉得差一点。 它不是完全不能用,但就是不够贴、不够准、不够稳。最气人的是,很多输出看着还像模像样,结果一跑就歪。
这种现象其实并不神秘。
如果非要总结一个最根本的原因,那就是:模型不是在理解你的真实意图,它是在根据输入信号,推断最可能的答案形态。
信号越少,它猜得越多;信号越模糊,它越倾向于走通用套路。 于是就会出现那种很经典的结果:说得都对,但不是你要的;细节很多,但关键边界没对上;表面可用,但一落到真实项目就各种别扭。
还有一个很有意思、也很值得警惕的信号:当大模型开始一本正经地告诉你 You are absolutely right 的时候,你反而要格外小心。
因为很多时候,这种过于顺滑、过于迎合、几乎不带迟疑的认同,并不意味着它真的理解了你的问题,恰恰可能意味着它已经进入了一种顺着你说、帮你把故事补圆的模式。表面上看,它是在确认你的判断;但实际上,它也可能是在沿着一个错误前提继续往下生成,并且把这个错误包装得越来越像那么回事。
这就是为什么,在 AI Coding 场景里,我一直觉得:被认同,不等于被验证。 模型越是斩钉截铁地附和你,越要回头检查:前提是不是对的,边界是不是漏了,验证是不是做了,结论是不是只是“听起来合理”。
在实际场景里,这种 看起来对、跑起来错 的原因,大致集中在几类。
上下文不全:模型只能靠猜
这几乎是所有问题的源头。你没告诉它项目的目录结构、依赖版本、已有约定、团队规范、输入输出格式、测试路径,它就会默认采用最常见的世界观来补全。 这种补全最危险的地方在于:它往往并不离谱,甚至还很顺眼,所以更容易让人放松警惕。
改动过大:一下子把可控性打没了
很多人一上来就喜欢让 AI把这个模块整个重构掉,顺便把相关测试也一并更新。听起来很省事,实际却很容易把 review、定位和回滚都搞得很痛苦。 你看起来节省了对话次数,实际上是在给后面的排错埋雷。
没测试、没基线:它说修好了,你也只能信
AI 很喜欢一本正经地告诉你“问题已经修复”,“已经优化完成”,“已兼容边界场景”。如果没有最小测试基线,这些话基本都只能当参考。 更现实一点说,没有可跑的验证,所谓修复很多时候只是换了一个地方出问题。
工具或代理越权:它不是恶意,但后果可能很恶心
一旦进入 Agent 或 CLI 场景,模型就不只是输出文本,而是能改文件、删文件、跑脚本、装依赖、操作终端。 这个时候最大的风险已经不是答得不对,而是做得太猛。如果你没有权限控制、没有操作边界、没有最小回滚策略,它完全可能对仓库做出不可逆的破坏。
风格漂移、架构散掉:今天快,明天贵
这类问题不会在一开始暴露,但会在之后的开发过程中开始反噬。没有统一规范时,AI 每轮都可能沿着不同风格生成不同实现。 久而久之,代码库会出现命名混乱、抽象层次不一致、异常处理风格漂移、模块边界松动等问题。 你看着像是在快速迭代,实际上是在给未来的维护成本开复利。
说到底,这些问题都不是什么科幻问题,它们非常朴素,就是软件工程里的老毛病,只不过 AI 把它们放大了。
因此我一直反感两种极端言论:一种说 AI Coding 是未来,大家以后都不用写代码了;另一种说 AI Coding 全是垃圾,会把团队带进沟里。 现实往往没那么极端。它既不是自动驾驶,也不是全无价值。它更像一套新的动力系统——你得先知道路怎么走,车才开得稳。
AI 编程工具怎么选
如果要问我怎么看待当前常见的 AI 编程工具,我的总体态度一直很朴素:先看场景,再看工具,不要反过来。
因为不同工具之间当然有差异,但它们真正拉开体验的,不仅是模型强弱,更是交互方式和适用任务。
我习惯把常见使用场景分成四类:补全、对话、Agent、终端。
补全:当你其实已经知道自己要写什么
补全类工具最适合的前提是:你脑子里已经有大体实现路径,知道改哪里、写什么、差不多长什么样。 这个时候 AI 的价值主要是减少键盘输入、补掉重复代码、缩短样板劳动。
像 GitHub Copilot 这类深度集成 IDE 的工具,在这个场景里就很顺手。它不会强行打断你本来的工作流,也不要求你突然切换成很重的对话式编程。 你在熟悉的编辑器里继续干活,它负责在恰当的时候递上一段建议。
这类工具特别适合熟悉代码库、改动范围明确的任务。你知道自己在做什么,只是不想手敲每一个重复结构。
对话:当你最缺的不是代码,而是理解
很多人其实低估了对话场景的价值。大家容易把 AI 当成生成器,一心只想让它快点出代码。 可在真实工作里,你经常更缺的是理解成本的下降:一段陌生代码怎么读,一个模块为什么这么拆,一次重构的风险在哪,几个方案各自的 trade-off 是什么。
这个时候,通用大模型对话工具非常好用。ChatGPT、Claude、DeepSeek、ChatGLM 这类应用,哪怕不直接落在 IDE 里,也可以成为很强的思考辅助。 尤其在需求确认、架构分析、概念理解、技术选型这些阶段,对话式使用往往比直接上手生成代码更划算。
我自己的经验里,这种对话其实占了很大比例。不是每一次 AI 介入都要落成代码。 有时候你只是需要一个足够耐心、反应够快、知识覆盖够广的技术讨论对象,帮你先把思路理顺。 很多返工就是在这个阶段避免掉的。
Agent:把需求变成流水线
当任务开始跨多个文件、需要跑命令、读日志、改代码、生成摘要、输出 PR 说明时,Agent 类工具就会开始体现优势。 它们更接近一个能分步执行任务的代理,不只是回答问题,而是会围绕目标持续行动。
像 Cline 这类工具,Plan 和 Act 模式的分离就很有代表性。你可以先要求它规划,再决定让它执行。 这个设计非常重要,因为它能在一定程度上避免模型不经讨论直接大改的风险。 你先看它打算怎么做,觉得合理再放行,整体可控性会好不少。
但 Agent 最大的价值也是最大风险:它能动。能动,就意味着速度快;能动,也意味着一旦边界不清,代价会比纯文本回答更高。
终端:离开 IDE 之后,AI 仍然能工作
CLI 场景是很多人最近才开始重视的部分。终端类 AI 工具适合那些可脚本化、可批处理、可远程执行的任务, 比如 SSH 场景、CI 环境、批量修复、自动化检查、变更摘要生成等等。
Gemini CLI 一类工具的吸引力就在这里:它不是围绕编辑器里的几行代码展开,而是更接近一套可在命令行里参与工作流的智能能力。 对运维、脚本化任务、仓库级操作来说,这种形态尤其有价值。
所以与其争论哪个工具最好,不如先问一句:你现在是要补全、要理解、要代理执行,还是要在终端里做自动化?
场景对了,工具自然更容易发挥。场景错了,再强的模型也会让你觉得别扭。
工具只是入口,真正拉开差距的是你会不会构建语境
讲到这里,就必须进入这篇文章里我最想展开的一部分:Prompt。
因为在我看来,AI Coding 里真正的重中之重,不是你选了哪一个工具,而是你有没有能力把任务写成一个语境完整、可执行、可验证的说明。
这也是为什么我越来越不喜欢把 Prompt 简单理解为提问。
很多人对 Prompt 的理解,还停留在问得更聪明一点。但在工程场景里,Prompt 更准确的本质其实是:把你脑子里的标准,外化成模型可以执行的规格说明。
为什么简单 Prompt 容易平庸?原因并不复杂。你不给约束和标准,模型就只能猜你的真实目标。它一旦开始猜,就会优先走风险最低的通用套路。 你没给上下文,它就会补一堆训练中常见但未必适合你当前项目的答案。你没指定输出结构,它就会给你一个看起来通顺、但难以复用和评审的大段文本。 于是最终结果就成了那种很典型的都对,但没用的输出:看不出你的偏好,没有体现你的边界,结构也松散,没法直接落地。 这不是模型故意跟你作对,而是它在信息不足时的合理策略。它会用最常见的模式来兜底。 所以真正的解法不是写更花哨的 Prompt,而是把语境补齐。

用一句话来概括,就是:
把品味、方法、约束、输出格式,显式写出来。
具体来说,一个工程场景下足够好的 Prompt,至少要包含四块内容。
目标:你到底想解决什么问题
这里不是泛泛地说帮我优化一下,而是说清楚成功标准是什么。你更在意可读性还是性能?更在意减少重复还是降低耦合?有没有优先级?哪些取舍是允许的,哪些不是?
方法:你偏好的做法是什么
模型并不知道你喜欢什么样的架构风格,也不知道你对抽象粒度、命名方式、异常处理风格的偏好。你不说,它就只能按最常见的办法来。 适当给出方法偏好、参考范例、反例,能极大减少说得都对但不是你想要的情况。
约束:边界在哪里
这是最容易被忽略、但又最重要的部分。哪些东西不能改?不能引入什么依赖?要兼容什么版本?不能改变哪些接口语义?性能和安全有没有硬限制? 如果没有这些边界,模型会非常自然地用最好写的方式解决问题,而不是最适合你项目的方式。
输出:你希望它怎么交付结果
你是要先给方案摘要,再给代码?还是先列风险点,再给实施步骤?需要按文件分段输出吗?需要附验证命令和自检清单吗?输出结构一旦固定,结果就更容易复用、对比和评审。
所以我非常赞成把 Prompt 写成这种形态:
- 先明确角色,再说明任务;
- 给出背景信息;
- 写清约束边界;
- 规定输出格式;
- 补上验收标准。
你会发现,这时候 Prompt 已经不太像问句了,它更像一份轻量级的任务说明书。
而这,恰恰才是工程场景里真正有用的 Prompt。
高效使用 Prompt 的核心,是减少猜测
我经常会看到一种很可惜的使用方式:用户把模型当成老虎机,一次次换提示词,期待某次突然摇出大奖。 今天试一句,明天换个语气,后天再加个请认真思考,如果结果不好,就怀疑是不是换个模型、换个姿势、换个玄学咒语就会变强。
说得直接一点,这种方法偶尔也许能撞到好结果,但它没法稳定复现,更没法迁移到团队协作里。
因为软件开发不是抽奖。你不可能每次都指望运气好,恰好让模型猜中你脑中的隐含约束。
Prompt 的价值,不在于让模型更聪明,而在于让模型少猜一点。
这是我对 Prompt 工程最核心的理解:它不是语言魔法,而是信息组织能力。你要做的,不是玩词藻,而是把任务写得清楚、完整、可检查。
我甚至越来越觉得,一个人和模型长期交互之后,最应该反思的不是模型为什么不稳定,而是我表达标准的方式是否稳定。 很多时候,我会习惯性的先给定前提条件,于是在和模型对话时,会频繁地使用这样一类的表达,比如:
- 围绕某某内容,展开…;
- 基于某某背景,分析…;
- 针对某某场景,优化…;
- 在某某情况下,给出 … 建议。
真正好的 Prompt,不一定华丽,但一定有可执行性。它让模型知道:
- 你是谁;
- 现在在什么项目里;
- 你要解决什么问题;
- 什么不能做;
- 什么叫完成;
- 最后要交付成什么形态。
当这些信息齐了,模型输出自然就会更稳。
所以我很认同一句提醒:不要把大模型变成老虎机,不要用掷骰子的心态和它交互。
你不是在赌一个好答案从天而降,你是在设计一个任务如何被更可靠地执行。
常见 Prompt 范式
很多人一提到 Prompt Engineering,就容易被一串缩写绕晕:Zero-shot、Few-shot、CoT、ToT、ReAct、Self-consistency、Step-back……看上去像是要背一本新的技术词典。
但其实不需要把这件事搞得那么学术。对大多数人来说,更实用的理解方式是:这些范式不是要你膜拜的概念,而是你可以灵活组合的搭积木工具。

Zero-shot / One-shot / Few-shot
这是最直观的范式。你不给示例,模型就要完全靠理解任务来生成;你给一个例子,它会去模仿风格;你给几个多样的例子,它更容易对齐格式和质量预期。
这在写代码、写文档、写测试、写摘要时都很有用。尤其当你对输出格式有明确偏好时,少量高质量示例比一长串抽象要求更有效。
Role / Contextual
先定义它是谁、处在什么环境里,这个很好理解。你先告诉模型它扮演什么角色,是后端工程师、架构师、代码审查者、Prompt Builder,还是测试工程师; 再告诉它当前项目的语言、版本、目录、约束,它的输出就更容易贴近工程现实。
很多所谓模型不懂我项目,其实不是它笨,而是你根本没让它进入项目语境。

Step-back
先退一步抽象,再回到具体任务,这个方法我个人很喜欢。因为很多任务一上来直接求答案,容易头痛医头、脚痛医脚。 先让模型退一步,总结原则、抽象问题本质,再回到具体实现,常常会更稳。 比如先问“这种重构的核心目标是什么”,“这一类鉴权问题的本质约束是什么”,再问具体方案,往往比直接催它改代码更有帮助。
思维链(CoT)
思维链并不神秘,本质上就是让复杂问题拆成步骤。对于定位 bug、设计方案、排查依赖、拆实现任务来说,逐步分解能让输出更容易 review,也更容易发现它在哪一步开始跑偏。
Self-consistency
先提供多条路径,再选最一致的答案。这个更像一种稳定性增强办法。让模型生成多种推理路径或多个候选方案,再根据一致性或评估标准选择结果,能降低偶然性。 它很适合那些对正确性要求高、而单次生成容易摇摆的问题。
思维树(ToT, Tree of Thoughts)
思维树在 AI Coding 里尤其适合那些路径很多、风险不同、需要比较取舍的任务。 比如架构拆分、复杂重构、性能优化方案组合这类问题,不是一条直线往前走,而是要并行探索多个候选分支,再按标准评估、剪枝、收敛。
但 ToT 最常见的坑也很明显:分支看似很多,实际同质化;评估维度太空;最后只选了方案,却没有设计验证和回滚。
ReAct
推理、行动、观察,形成闭环。这是我觉得最适合和工程实际类比的范式,因为它特别像 OODA 循环:观察、判断、决策、行动,然后再观察结果。
在代码场景里,它意味着什么?
- 先读代码、看日志、跑测试、看目录;
- 再基于现象提出假设;
- 然后选择一个最小行动去验证;
- 最后看结果是否符合预期,不符合就更新假设。
ReAct 的价值,不在于显得很聪明,而在于它把想清楚和动手做串成了一个闭环。 最大的问题则是:很多人让模型直接大动干戈,一次改太多,或者盲跑一堆工具、打出满屏日志,却没有明确期待看到什么现象。 这样就很容易把行动变成噪音。
我更愿意把这些 Prompt 范式看成一套乐高积木。任务不同,积木组合不同。 真正重要的不是记住术语,而是知道什么时候该给例子,什么时候该先抽象,什么时候该拆步骤,什么时候该让行动和观察形成闭环。
写高质量 Prompt 的四条路
如果前面说的是原理,那接下来我想谈谈更实用的一层:到底该怎么把 Prompt 写好?
在长期实践里,我越来越觉得,高质量 Prompt 的形成,大致有四条常用路径。 它们不是互相排斥的,而是四种补齐语境的方法。你处在什么信息状态,就选什么路径。
方法一:自己写详细指令
当你对任务本身非常熟,知道目标、边界、风险、输入输出都是什么,最快的办法就是自己把这些信息一次写全。
这种方法最适合领域熟手。因为你不需要先和 AI 反复确认问题本身,而是可以直接把任务压缩成一份高密度、低歧义的说明。 它的核心不是写很多,而是把关键信息写齐:角色、场景、问题、输入、输出、约束、风险、验收。
就像我在之前提到的那样,可以固定一个最小模板:
- 你是谁;
- 我们在什么场景里解决什么问题;
- 输入是什么;输出是什么;
- 约束有哪些;
- 风险点是什么;
- 验收怎么做。
这个模板看起来朴素,但非常有用。因为它迫使你在生成之前,先把隐形标准显式写出来。
方法二:先让 AI 写框架,再迭代补全
不是所有任务你一开始都想得那么清楚。有些时候,你知道大方向,却不知道细节里缺了什么。这个时候,与其勉强一次写完,不如先让 AI 帮你搭一个可讨论的骨架。
- 比如先让它输出 v0:目标、模块、接口、验收思路;
- 然后要求它主动追问 3 到 5 个最影响设计的关键问题;
- 你逐项回答后,它再迭代成 v1、v2,并附上变更记录;
- 最后再把稳定版本固化成真正用于执行的 Prompt。
我很喜欢这种做法,因为它不像直接生成代码那样一头扎进实现,而是先让任务定义本身收敛下来。很多时候,真正值钱的不是第一版答案,而是第一轮问对的问题。
方法三:先用权威材料做语境底座
当你自己也不完全确定正确做法时,就不要只凭感觉描述。最稳的做法,是先引入官方文档、规范、最佳实践、团队经验,让 AI 只基于这些材料提炼成可执行规范,然后再把规范压缩成 Prompt。
这个方法特别适合鉴权、安全、协议、框架最佳实践、组织内部规范等场景。因为这类问题最怕似懂非懂的通用答案。 先把材料喂进去,再要求 AI 标出依据和不确定点,它生成出来的东西才更可信,也更适合团队复用。
方法四:复刻成熟成品的结构
有时候你想要的不是某个点状答案,而是一整套结构默认值。这时候,找一个你认可的成熟开源项目、模板或脚手架, 让 AI 先拆解它的技术栈、模块边界、关键流程、为什么这样设计有效,再输出一份可复刻指南,会非常省事。
这并不是让 AI 机械抄袭某个项目,而是借成熟样板来替你定义默认答案:目录怎么分、流程怎么走、哪些结构建议保留、哪些地方可以替换。 对于新项目启动、团队规范统一、技术栈迁移来说,这种方法特别实用。
这四种方法背后其实是同一个原则:
- 你可以自己写全;
- 可以通过对话逐步补全;
- 可以借权威材料校准;
- 也可以借成熟结构定形。
无论哪条路,最终都要落到两件事:可执行清单和验收标准。否则再漂亮的 Prompt,也只是看起来很懂的文字。
Meta Prompt
如果说前面讲的是怎么写某一个 Prompt,那么 Meta Prompt 关注的是更高一层的问题:怎么稳定地产生高质量 Prompt。
我越来越觉得,很多人低估了这件事的重要性。大家常常愿意花很多时间打磨某次 AI 输出,却不愿意花一点时间沉淀以后怎么更快得到类似质量的输入模板。 结果就是每次都从零开始,每次都重新试错,每次都重走同样的弯路。
这很像写代码时不抽函数、不做复用。短期看省事,长期看全是重复劳动。
Meta Prompt 的意义,就在于把写 Prompt 的方法本身也结构化、模板化。你先教 AI 如何根据任务、材料、项目上下文和验收标准,自动生成一份更完整的执行 Prompt。 这样你每次面对新任务时,不是从空白开始,而是从一个质量更高的草稿开始。
我特别认同这样一个工作方式:
- 先把 AI 当作一个按指令执行的数字员工;
- 不要一上来就让它直接交成品;
- 先让它根据材料生成详细指令;
- 再把这份详细指令转成具体 Prompt;
- 如果信息不够,先问少量关键澄清问题;
- 最后按固定结构输出角色、计划、约束、验证和交付格式。
这样做的好处非常明显。
- 第一,它让 Prompt 从临场发挥变成可复用流程。
- 第二,它降低了每次从头组织语境的心智负担。
- 第三,它更适合团队协作,因为别人也能沿着同一套结构理解和复用你的做法。
- 第四,它让 Prompt 变成一种资产,而不是一次性的聊天记录。
从这个角度看,好 Prompt 不应该只活在某个人的历史对话里,而应该被保存、迭代、版本化,逐步沉淀成团队自己的 Prompt 库。
这也是为什么我很看重 Prompt 的版本管理。你会发现,真正能产生复利的,不只是代码模板,还有任务表达模板。
把 Prompt 作为工程资产进行管理
很多团队已经习惯对代码做版本管理,却很少对 Prompt 做同样严肃的管理。可如果你真的把 AI 纳入日常开发流程,就会发现 Prompt 本身也在承担越来越重要的职责: 它决定输入质量,影响输出稳定性,承载项目上下文,甚至会影响团队协作的一致性。
既然如此,它当然值得被管理。
我很喜欢用Prompt 库条目这种方式来组织一类可复用任务(参见 《Prompt Engineering - Author: Lee Boonstra》)。一个条目至少可以包含这些字段:
- 名称:这是用来干什么的,比如补丁生成、重构建议、缺陷定位;
- 适用场景:什么情况下用,什么情况下不该用;
- 输入字段:哪些材料必填,哪些可选;
- 约束:边界、风格、禁止项;
- 验收:什么叫成功,怎么验证;
- 输出格式:希望它按什么结构交付;
- 版本:v0、v1、v2……有哪些变更记录,已知问题是什么。

你会发现,这跟管理一个小型工程规范其实很像。因为 Prompt 的作用已经不只是帮我问一句,它是在替你定义一类任务的默认执行方式。
一旦你开始这么做,Prompt 就不再是一段散落在聊天记录里的临时文本,而是一套真正能复用、能协作、能持续打磨的资产。 你甚至能比较不同版本的 Prompt 对结果质量、稳定性、返工率有没有影响。这个时候,所谓Prompt Engineering才真正从玄学变成工程。
Prompt 最佳实践
关于 Prompt 最佳实践,网上已经有很多清单式总结了。但如果只背清单,不理解背后的原理,很容易变成机械套模板。 这里我更想从为什么这些做法有效的角度,重新总结一遍。
把长句拆成短句,把任务拆成步骤
模型处理信息时,不怕你结构化,最怕你把多个要求揉成一团。人也一样。把复杂任务拆成清晰步骤,不只是为了模型,也是为了你自己能检查有没有漏项。
把指令放在前面,把材料和上下文分隔开
这背后的逻辑很简单:让模型先知道该做什么,再知道基于什么做。如果任务、材料、示例、附加说明混成一坨,它更容易抓错重点。
用具体指令,而不是模糊形容词
“写得专业一点”,“优化一下体验”,“提升质量”这些表达本身信息量很低。相比之下,明确目标、范围、长度、格式、风格、禁止项、验收方式,会让输出更接近你真正要的结果。
用期望模板或示例定义输出格式
很多输出质量问题,根本不是内容不行,而是形式太松散。只要你给出一个清晰的输出模板,模型在复用和评审上的表现都会稳定很多。
先 Zero-shot,不够再 Few-shot
这条建议我很认同。先看模型在没有示例时能否完成任务,可以帮助你判断问题究竟出在语境不足,还是格式对齐困难。如果一开始就塞大量示例,有时候反而会掩盖真正的问题。
少写不要做什么,多写应该怎么做
纯负向约束容易让模型留在一个很大的模糊空间里。你告诉它不要那样,不代表它知道应该怎样。正向指令配合边界和替代方案,通常更有效。
用 Markdown 做结构化表达
标题、列表、代码块、标签前缀,这些不是排版洁癖,而是为了降低模型理解和你后续维护的成本。结构清楚,信息检索和复用都会更轻松。
固定 Prompt,跨模型对比测试
很多人只在一个模型上反复试,却很少验证同样的 Prompt 放在别的模型上表现如何。固定输入、比较输出,能帮你更客观地理解是 Prompt 本身有问题,还是模型特性导致的差异。
重要 Prompt 做版本迭代管理
这条前面已经讲过了。真正高价值的 Prompt,不是一次写完,而是不断优化。每一轮迭代都应该带来更明确的边界、更稳定的输出、更低的返工成本。
说到底,Prompt 最佳实践并不神秘。你可以把它理解成一种高质量任务说明的写法。它服务的不是模型,而是交付本身。
AI 加持下,团队开发流程为什么一定会变
聊完个人使用,再往上走一步,就是团队流程。
我觉得很多团队对 AI 的想象还停留在给每个人发个工具账号,效率自然就会提升。这种想法非常像过去那种买了协同软件,组织就数字化了的幻觉。 工具本身当然有帮助,但如果流程不变、角色不变、验收方式不变,AI 带来的加速很快就会撞上新的墙。
为什么?因为AI 让实现更快,但瓶颈会前移。
原来一个需求从提出到交付,最慢的环节也许是开发本身。现在实现速度被拉高之后,整个流程里最容易拖后腿的地方会变成:
- 需求定义不够具体;
- 验收标准不够清晰;
- 反馈回路太慢。
你会看到一种很典型的现象:
开发端很快,几乎当天就给出可运行版本;
产品端还在讨论这是不是我想要的;
测试端不知道应该按什么标准验;
业务方反馈又要隔几天才能回来;
最后所有人都觉得AI 明明让开发变快了,为什么项目节奏没快多少?
答案很简单:因为真正慢的地方已经不是写代码了。
所以在 AI 时代,团队流程一定会往三个方向改:
需求必须更具体
以前做个差不多还能靠经验兜住一点,现在不行。需求如果不具体,AI 只会更快地产生大量需要返工的实现。最小字段至少应该包括:目标、非目标、验收用例、风险与约束。
验收要尽量可跑
这可能是我最想强调的团队动作:把验收标准写成可运行的测试、脚本或检查清单。
因为只有这样,AI 加速实现的同时,验证也能跟着加速。否则所谓验收仍然停留在“感觉差不多”,“你看看像不像”这种非常低效的状态。
反馈要更短
AI 降低了试错成本,真正的竞争优势变成谁能更快把东西推到反馈环里,再更快修正方向。上线、观察、决策、回收数据,这一整套如果还是老节奏,那么实现端再快,收益也会被吞掉。
所以如果让我用一句话概括团队侧最重要的变化,那就是:
AI 把写代码这段变快了,但项目真正的输赢仍然在执行速度,而执行速度取决于需求、验收和反馈能不能同步升级。
这不是技术问题,是组织问题,也是协作问题。
如何安全有效落地 AI Coding
如果说前面讲的是怎么更高效地用 AI,那这里想讲的是一个更现实的问题:怎么别把自己和团队带进坑里。
因为 AI Coding 最危险的地方,从来不是它不会写,而是它写得太快、太像那么回事,以至于你很容易只留下代码,却把为什么这么做丢了。
这是我特别在意的一点。
过去团队开发即便文档不完美,很多关键意图也散落在会议、评审、口头对齐和代码注释里。现在 AI 加入之后,一次对话就可能生成大段实现,一次 Agent 执行就可能跨多个文件完成修改。 如果你只保留最后的代码 diff,而没有留下意图、约束、取舍和验收标准,后续维护就会变得像考古一样。
你能看懂代码,但你不知道当时为什么这么做。
你知道它能跑,但你不知道它故意没有覆盖哪些边界。
你知道现在这样实现了,但你不知道当时有没有讨论过别的方案,为什么没选。
这对团队协作和后续迭代都很伤。
所以我越来越认同这样一个总纲:
关键资产不是代码本身,而是规格 / 意图 / 约束 + 可执行验证。
AI 可以写实现,但人必须负责边界和验收。没有验证的 AI 改动,本质上就是不可控的加速。
那怎么做才更稳?我会把落地动作概括成四类。
规格文档:让意图成为可管理资产
需求文档不应该只是一段抽象描述,而应该升级成可验证规格。它至少要回答:目标、非目标、输入输出、边界条件、失败模式、安全约束。并且它要能被版本管理、可讨论、可追踪变更。
验收用例:让对错不再靠感觉
把验收标准写成能跑、能比对、能回归的用例。越关键的路径,越应该被写成自动化证据。否则评审时所有人都只能凭经验判断,这在 AI 加速之后会迅速成为瓶颈。
质量检查:把合并变得更可控
格式检查、类型检查、静态分析、依赖扫描、关键路径最小回归,这些东西不是为了显得流程严格,而是为了降低人在高频评审里的负担。AI 让改动更密集之后,没有质量闸门,团队会很快被 review 压垮。
提示与决策留痕:让协作可复盘
不是要记录每一句聊天记录,而是记录关键 Prompt、核心假设、重要取舍、最终结论。这样新人接手不需要靠问人,问题复盘也不需要靠回忆。
如果把这一套串起来,其实就是一个很标准的流程:
- 先写规格;
- 再写验收;
- 然后让 AI 写实现;
- 过质量闸门;
- 最后 review 只看三件事:规格有没有变形,验收有没有覆盖边界,风险有没有识别并处理。
我很喜欢一句收束:AI 能加速实现,但不能替你做判断。
真正可持续的效率,来自意图写清楚、验收可运行、改动可验证、协作可复盘。
AI 时代,个人真正该升级的,不是手速,而是交付能力
写到这里,其实已经能自然过渡到另一个大家都很关心的话题:在 AI 时代,个人到底该怎么成长?
我自己的看法一直比较直接:别回避现实。竞争一定会更激烈,只会写代码不再是稳态优势。
这句话不是危言耸听,而是一个很朴素的趋势判断。AI 会越来越多地覆盖编码、测试、文档、检索、排查这些工作环节。原来很多靠熟练度和体力堆出来的优势,都会被削弱。
但与此同时,有些东西反而会更重要:
- 你能不能把一个问题定义清楚;
- 你能不能把结果做成可运行、可复现、可评估的作品;
- 你能不能在团队里把沟通和决策结构化;
- 你能不能识别边界、控制技术债、承担结果。
说得再直白一点,个人竞争力会从会不会写转向能不能交付、能不能被验证。
所以我很认同一组更有效的成长策略:
做作品,而不是只做展示
作品的意义不是炫技,而是证明你真的能交付价值。它最好能让别人快速看懂:你解决了什么问题,怎么运行,结果长什么样。 一个能一键启动、有最小示例输入输出的作品,通常比十页讲概念的简历更有说服力。
让结果可评估,而不是只靠主观感觉
你做了什么不重要,重要的是别人如何判断它做得好不好。有没有指标?有没有基线对照?有没有边界说明?有没有失败模式? 这些内容一旦写清楚,作品就从我觉得不错变成别人可以复核。
会协作,而不是只会单点输出
AI 时代的沟通能力,不是会不会说漂亮话,而是能不能把需求、验收、风险、决策写得清楚,让别人可以接着你的信息继续推进。 很多时候,真正稀缺的不是某段代码,而是可追溯的团队共识。
懂边界,守住工程基本功
AI 会放大优点,也会放大缺点。你本来需求表达清楚、验证习惯好、工程意识强,它会让你更强。 你本来就爱偷懒、只追快、不爱测、不顾技术债,它也会让你更快出问题。
所以我越来越认同这样一种排序:
作品 > 证书;评估 > 感觉;基本功 > 花活。
这不是说证书没用,而是说在一个实现越来越容易被自动化的时代,真正能证明你价值的,是你能不能做出别人看得见、跑得动、复现得了、评估得清的东西。
一个更靠谱的作品集标准
为了让上面那部分不只是原则,我想再把它压缩成一个更可操作的个人标准:作品集三件套。
可运行:让别人最快看到你做了什么
最理想的状态是,对方用最小成本就能看到成果。最好有一键启动说明,或者最短运行路径。有示例命令,有最小示例输入,有预期输出截图或日志。 它不需要是大而全的生产系统,但一定要让别人知道你不是只会说,你真的把东西做出来了。
可复现:让别人相信这不是偶然
环境依赖、版本说明、步骤清单、常见坑提醒,这些东西看似琐碎,却非常重要。很多项目卡死不是因为做不出来,而是别人根本无法在自己的环境里跑起来。 可复现不要求完美,但至少要让别人照着步骤走,大概率能成功。
可评估:让好坏判断不靠感觉
你可以根据项目类型选择指标:速度、准确率、成本、稳定性、覆盖率、召回率、错误率……重点不是指标多,而是你得说清楚为什么这个结果算成功。 最好还有一个基线方案或旧版本对照,再加上边界说明和不适用场景。
我很喜欢把这三件事分别理解成:
- 可运行解决看见;
- 可复现解决相信;
- 可评估解决认可。
当你能持续产出这样的作品时,AI 不是在威胁你,反而是在放大你的价值。因为它帮你更快做出东西,但真正让别人服气的,还是你把东西做成证据的能力。
人机协作,最后拼的永远不是谁更会说,而是谁更会判断
写到最后,我其实想把整篇文章再拉回一个最根本的问题:我们到底应该用什么态度面对 AI Coding?
我的答案很简单,也很老派:永远不要放弃思考。
这句话听上去像废话,可在 AI 时代,它反而越来越像一个必须反复提醒自己的基本原则。 因为模型太容易给出像答案的答案,太容易让人误以为既然它已经说得很完整了,那我就不用再判断了。
可软件开发不是语文填空。
项目不是因为回答听上去很合理就会成功。
团队也不是因为代码已经生成出来了就自动获得了可维护性、正确性和价值。
人类真正要负责的部分,始终没有变:
- 定义问题和目标;
- 划定边界和约束;
- 做价值判断;
- 承担最终结果。
而 AI 真正擅长的,也应该被放在它擅长的位置上:
- 快速生成候选方案和实现;
- 降低探索和试错成本;
- 把重复劳动自动化;
- 提供多个方向供你比较。
最理想的人机协作状态,不是谁替代谁,而是形成一个更清晰的分工:
- 人把规格写清楚;
- AI 先去铺实现;
- 验证形成闭环;
- 最后把好用的做法沉淀成模板和资产。
如果一定要把这件事压缩成一句工作法,我会很愿意推荐这样一句话:每次交付,都同时交付:结果 + 证据 + 可复用资产。
- 结果,是这次做成了什么;
- 证据,是你怎么证明它做对了;
- 可复用资产,是这次的方法、模板、Prompt、规范、测试、脚手架,能不能让下次更快更稳。
这三样东西加在一起,才是真正的复利。
结语
如果要给整篇文章做一个收束,我大概会这么说:AI Coding 最迷人的地方,在于它真的把很多原本昂贵的实现工作变便宜了。 一个想法变成原型的距离缩短了,一个需求从文字到可运行结果的时间压缩了,一个人能同时覆盖的工作范围也扩张了。
但也正因为如此,很多过去被实现速度遮住的问题,现在会更赤裸地暴露出来:需求是否清楚,边界是否明确,验收是否可跑,反馈是否够快,团队是否能复盘,个人是否真正具备判断力。
所以我并不太关心AI 能不能取代人这种宏大问题。对个体和团队来说,更现实的问题永远是:
- 你有没有把 AI 变成自己的杠杆?
- 你有没有让工作方式随着工具升级?
- 你有没有在加速实现的同时,守住判断、边界和责任?
如果没有,那 AI 带来的很可能不是效率,而是更快的混乱。如果有,那它会成为一个非常夸张的放大器,放大你的表达能力、工程意识、验证习惯和交付水平。
说到底,技术一直都该为人服务。代码不是写给机器看的,最终也是写给人看的;需求不是为了喂给模型,而是为了更准确地解决人的问题;工具再新,也只是手段,不是目的。
AI 不会自动让你成为一个更好的工程师。但它会毫不留情地放大你现在的样子。这件事,既残酷,也公平。
所以,与其焦虑未来会怎样,不如从下一次真实工作开始,做几个很具体的动作:
- 把需求写得更具体一点;
- 把验收写成可跑的测试;
- 把关键 Prompt 和决策留痕;
- 把一次性的对话沉淀成可复用模板;
- 把会不会写升级成能不能交付、能不能证明。
当你真的这样做过几轮之后,你会发现,AI Coding 这件事不再只是一个热词,也不只是一个炫技演示,而会慢慢变成一种更扎实、更清醒、也更有复利的工作方式。
而这,可能才是它真正值得期待的地方。
参考资料
- YouTube: How To Use AI Better Than 99% Of People (This Changed My Life)
- YouTube: Stanford CS230 - Autumn 2025 - Lecture 9: Career Advice in AI
- YouTube: What Is Understanding? – Geoffrey Hinton - IASEAI 2025
- YouTube: Andrew Ng: Building Faster with AI
- YouTube: Vibe Coding Is The Future
- YouTube: From Vibe Coding To Vibe Engineering – Kitze, Sizzy
- YouTube: The New Code — Sean Grove, OpenAI
- YouTube: How I use LLMs
- Prompt Engineering - Author: Lee Boonstra
- Prompt Engineering Guide
- Context Engineering: Sessions, Memory - Authors: Kimberly Milam and Antonio Gulli
- Effective context engineering for AI agents
- Google Doc: Metaprompt
- After 1000 hours of prompt engineering, I found the 6 patterns that actually matter