 lane4dev
lane4dev
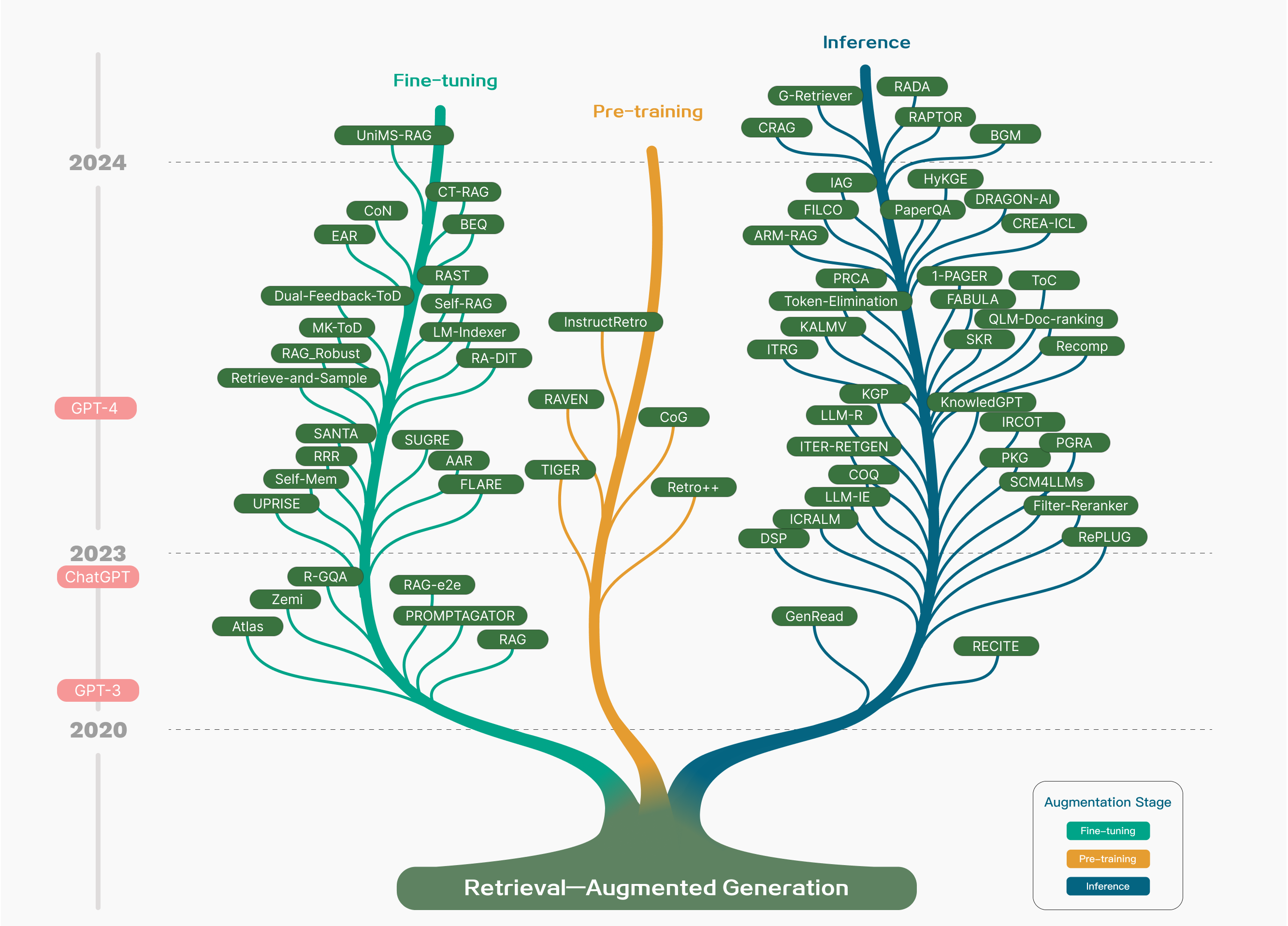
每次做 RAG 系统,我脑子里都有一堆散装概念:向量库、Top-K、HyDE、 Re-ranking、Self-RAG……但真要串成一套“完整方法论”时,总觉得缺一块拼图。
《RAG for LLM: A Survey》这篇综述,某种程度上帮我把这些碎片理了一遍: 从最朴素的 Naive RAG,到开始动脑子的 Advanced RAG,再到可以像乐高一样拼装的 Modular RAG, 它不只是给了一份“技术清单”,更像给了一张思路地图。
于是我就顺手做了这篇读书笔记,一方面帮自己梳理三代 RAG 的共性和分工(检索 / 生成 / 增强过程), 另一方面也留个“检查表”:以后再搭 RAG 系统时,可以回来看一眼,确认自己不是又停在“上个向量库就开工”的那一步。
三种 RAG 范式
Naive RAG
典型流程:
索引 → 检索 → 生成(“Retrieve-Read”)
- 索引:文档清洗 → 统一成文本 → 按 token/段落切成 chunks → 向量化 → 存到向量库。
- 检索:把用户 query 也向量化 → Top-K 相似 chunk。
- 生成:把 query+检索到的 chunk 拼成 prompt,丢给 LLM。
优点:简单、可落地、ChatGPT 出来后很多 Demo / 产品都是这一套。
主要问题:
- 检索:该找的没找着,不该来的来了一堆(召回 & 精排都一般)。
- 生成:即便给了正确上下文,LLM 仍然可能幻觉、偏题、输出有害内容。
- 增强:复杂问题只靠“一次检索 + 一次回答”往往不够,容易冗余或割裂。
适用场景:快速原型 / 小文档 / 宽松场景,只要大致靠谱即可。
Advanced RAG
Advanced RAG 的主线是:
检索前做优化 + 检索后做优化
检索前(Pre-Retrieval):
-
索引优化:
- 更聪明的分块策略:Recursive split、滑动窗口、Small2Big 等。
- 给 chunk 加元数据(时间、类型、来源、摘要)。
- 用层次结构或 KG 做结构索引。
-
查询优化:
-
Query Rewrite / Expansion / Transformation:重写、扩展、抽象原始问题(如 HyDE 先生成“假答案”再检索, Step-back Prompting 提出更抽象的“回退问题”)。
-
Query Routing:根据语义或元数据,路由到不同数据源或索引。
-
检索后(Post-Retrieval):
- Re-ranking:用专门的排序模型或 LLM 重新排一遍 chunk。
- 上下文压缩:只留关键句子 / 段落,避免 prompt 巨长且全是噪音。
关键点:混合检索(稀疏 BM25 + 密集向量)、Small2Big、HyDE、Re-ranking、Context Compression。
Modular RAG
Modular RAG 把系统拆成一堆可以替换/组合的模块,例如:
- 搜索模块(Search Module):直接面向搜索引擎、SQL、KG,用 LLM 生成查询语句。
- RAG-Fusion:多 query 并行检索 + 智能融合结果。
- 记忆模块(Memory):维护长期“对话/任务记忆”,指导后续检索。
- 路由模块(Routing):在“查 KB / 调 API / 调别的 Agent”之间做选择。
- 预测模块(Predict):直接生成上下文,减少无关检索。
- 任务适配器(Task Adapter):一套 RAG 底座上接不同下游任务。
以及一系列新的模式:
- Rewrite-Retrieve-Read:先让 LLM 重写/拆解问题,再检索。
- Generate-Read / Recite-Read:用 LLM “背一下 + 检查一下”,增强参数内知识和外部检索的协作。
适用场景:复杂业务 / 多数据源 / 需要高度可控和可扩展的系统。
三大模块
检索(Retrieval)
检索源 & 粒度
- 数据源:非结构化文本、半结构化(PDF/HTML)、结构化(KG/表)、模型生成内容等。
- 粒度:从 token 到句子到段落再到文档,粒度越粗上下文越丰富但噪音越多。
索引优化
-
分块策略:
固定长度 / 滑动窗口 / 递归分块 / Small2Big(用小粒度检索,大粒度补上下文)。
-
元数据附加:
时间、来源、类别、作者、摘要、反向问题(Reverse HyDE)等,用于过滤和时间感知检索。
-
结构化索引:
层次结构(文档 → 章节 → 段落)+ 摘要;
知识图谱索引(KGP):节点表示段落/实体/结构单元,边表示语义相似、结构关系等,便于多跳检索和推理。([arXiv][1])
实用建议:别停留在“固定 512 token 切块 + 生嵌入”,层次结构 + 元数据基本是必须的。
查询优化
-
Query Expansion:多视角 query,子问题分解(Least-to-Most),CoVe 等验证链。
-
Query Transformation:
- Query Rewrite(如小 LLM 专门负责“把用户自然语言改成易检索问题”);
- HyDE(先写“假答案”,用假答案嵌入去检索);
- Step-back Prompting(先问一个更抽象的问题,再回到具体问题)。
-
Query Routing:
- 元数据路由:按时间/类型过滤;
- 语义路由:不同 type 的问题走不同 KB / 模块。
嵌入 & 混合检索
- 稀疏(BM25, TF-IDF):字面匹配强、对罕见实体敏感。 。
-
密集(BERT/BGE/其他专门 Embedding):语义匹配强。
-
混合检索:
- 稀疏先做粗筛,密集再精排;
- 或两个打分加权融合。
-
嵌入微调:
- 在医疗/法律等领域数据上做对比学习微调;
- 用 LLM 的回答/偏好做监督信号(LSR、REPLUG、LLM-Embedder 等)。
实用建议:通用 Embedding + BM25 起步可以,但只要是垂直领域,微调和混合检索迟早要上。
适配器(Adapter)
-
当你没法/不想微调大模型时:
-
用外部适配器来做 Prompt 检索、任务路由或“检索结果 → 可用上下文”的桥接(如 BGM)。
-
适配器可以是小模型、规则系统,或一个 Seq2Seq。
-
生成(Generation)
上下文筛选(Context Curation)
-
Re-ranking:把更相关的 chunk 排在前面;可用专门排序模型或直接用 LLM。
-
Context Compression:
小模型或专门“压缩器”负责抽取关键句/摘要,减轻 LLM 压力, 解决“Lost in the Middle”——模型只看开头/结尾,中间一片死区的问题。
LLM 微调(Fine-tuning)
-
目的:
领域适配:补齐专业术语 & 写作风格;
任务适配:特定输出格式 / 风格(比如你现在写的各种技术文档模板)。
-
方式:
预训练 → 指令微调 → 对齐(RLHF / LLM-as-a-judge)。
检索器 & 生成器联合优化,让二者的“相关性打分”更一致。
增强过程(Augmentation Process)
Iterative Retrieval:迭代检索
- 生成一段 → 发现信息不够 → 发起新一轮检索;
- 检索结果再反过来修正生成,往往比一次查完更贴题。
Recursive Retrieval:递归 / 多跳检索
- 把复杂问题拆成子问题,用 CoT/ToT 带着检索一步步深入。
- 特别适合需要跨文档、多实体、多关系的场景,比如政策解读、专利对比。
Adaptive / Self-RAG:自适应检索
让模型自己判断:
- 什么时候需要再查?
- 什么时候应该停?
典型做法:Flare(按置信度触发检索)、Self-RAG(反思 token,决定“检索/质疑/继续写”)。
实用建议:把“检索”当成一个可以被 LLM 主动调用的工具,而不是 pipeline 里固定的一步。
任务与评估
论文把 RAG 的评估拆成三块:任务、评估目标、评估工具。
下游任务
- 问答 QA(单跳、多跳、长文档、领域 QA)。
- 信息抽取(事件/关系)、对话、代码搜索、分类、摘要等。
评估目标
- 检索质量:命中率、MRR、NDCG 等。
-
生成质量:
- 忠实性(Faithfulness):有没有瞎编;
- 相关性(Relevance):是不是回答了问题;
- 安全性 / 有害性。
-
能力维度:
- 抗噪(Noise Robustness);
- 能不能诚实说“我不知道”(Negative Rejection);
- 多文档整合能力(Information Integration);
- 对错误/反事实的鲁棒性(Counterfactual Robustness)。
评估工具 & Benchmarks
- 工具:RAGAS、ARES、TruLens 等自动评估框架。
- Benchmarks:RGB、RECALL、CRUD 等,对鲁棒性、对抗样本、复杂任务做系统测试。
实用建议:做 RAG 项目时,最好一开始就决定:我要评哪三件事?用什么工具?不然永远停留在“看几条样例觉得挺好”这种想法里。
挑战与未来方向(论文视角)
论文的 讨论(Discussion) 部分主要围绕几个方向展开:
-
长上下文 vs RAG
- 长上下文可以替代一部分检索,但信噪比 & 推理效率问题仍然存在;
- RAG 更像是“主动控场”,有意地只给模型看关键内容。
-
鲁棒性 & 可信度
- 噪声、矛盾信息、对抗输入都会让 RAG 变得不靠谱;
- 未来会有越来越多“Trustworthy RAG”的研究(隐私、安全、公平、可解释等)。
-
RAG + Fine-tuning 的混合路线
- 微调负责“写得好”;RAG 负责“查得准”;
- 如何做联合训练 / 交替使用,是未来一条重要路线。
-
Scaling Law:模型大小 vs RAG 效果
- 一些结果显示:小模型 + 好的 RAG,在特定知识密集任务上不输大模型;
- 对“在多大规模下 RAG 还值得、怎么投入资源”是个很现实的工程问题。
-
生产环境 & 工程实践
- 检索效率、成本控制、数据安全、权限与审计,都需要系统设计;
- 工程工具链(LangChain、LlamaIndex 等)正在把这些东西变成“可复用组件”。
-
多模态 RAG
- 不只文本,还包括图像、音频、视频、代码等;
- 已有专门的 GraphRAG / Multi-modal RAG survey,可以和本篇一起看。
给自己的备忘录
以后做 RAG 系统,可以用这篇文章当检查表:
-
我现在做的是哪一代?
- Naive:只做“向量库 + Top-K”;
- Advanced:有没有做 Query 重写、Re-ranking、压缩?
- Modular:有没有考虑路由、记忆、搜索模块、任务适配器?
-
检索这块是不是太“摆烂”?
- 分块、元数据、结构索引有没有认真设计?
- 稀疏 + 密集混合了吗?有无领域微调?
-
增强过程有没有留给模型“思考空间”?
- 是否支持多轮/迭代/递归检索?
- 模型能不能自己决定“该不该再查一下”?
-
评估怎么落地?
- 至少弄清楚:我要评检索质量还是回答质量?
- 能否引入 RAGAS / TruLens 之类做一个最小可用评估闭环?
-
这篇 Survey 对我的价值
- 当作:RAG 技术词典 + 方案脑图。
- 想引文献/找具体方法名 → 回到论文 / alphaxiv 概览。