 lane4dev
lane4dev

FinGLM 源于 SMP 2023 ChatGLM 金融大模型挑战赛,核心任务是: 在 上市公司年报/财务报表 构建的知识库基础上,使用 ChatGLM 系列模型完成财报问答。 参赛系统需要围绕 PDF 年报回答三类问题:
- 基础查询(初级): 例如“某公司 2021 年研发费用是多少?”,直接从年报原文中抽取答案。
- 统计与计算(中级): 例如“某公司 2021 年研发费用增长率是多少?”,需要进行同比、环比等统计计算。
- 开放性/分析题(高级): 例如“某公司 2021 年主要研发项目是否涉及新能源技术?”,需要结合年报文本进行综合分析和推理。
典型原始数据形式为 PDF 财务报表,如交易所披露的年度报告文件。
总体技术路线概览
结合多支队伍的公开方案,可以把 FinGLM 的技术路线概括为三层:
- 问题理解与分解:问题分类、意图识别、关键词抽取、复杂计算题拆解;
- 文档处理与知识组织:PDF 解析、文档树构建、表格语义化、要素级语义解析;
- 检索与推理回答:基于关键词+向量的混合检索,构造问题链,逐步求解并生成自然语言答案。
下文将以 馒头科技、吃辣子、ChatGLM 反卷总 三个方向为主线,说明各自的技术路径与侧重点。
方案一:馒头科技
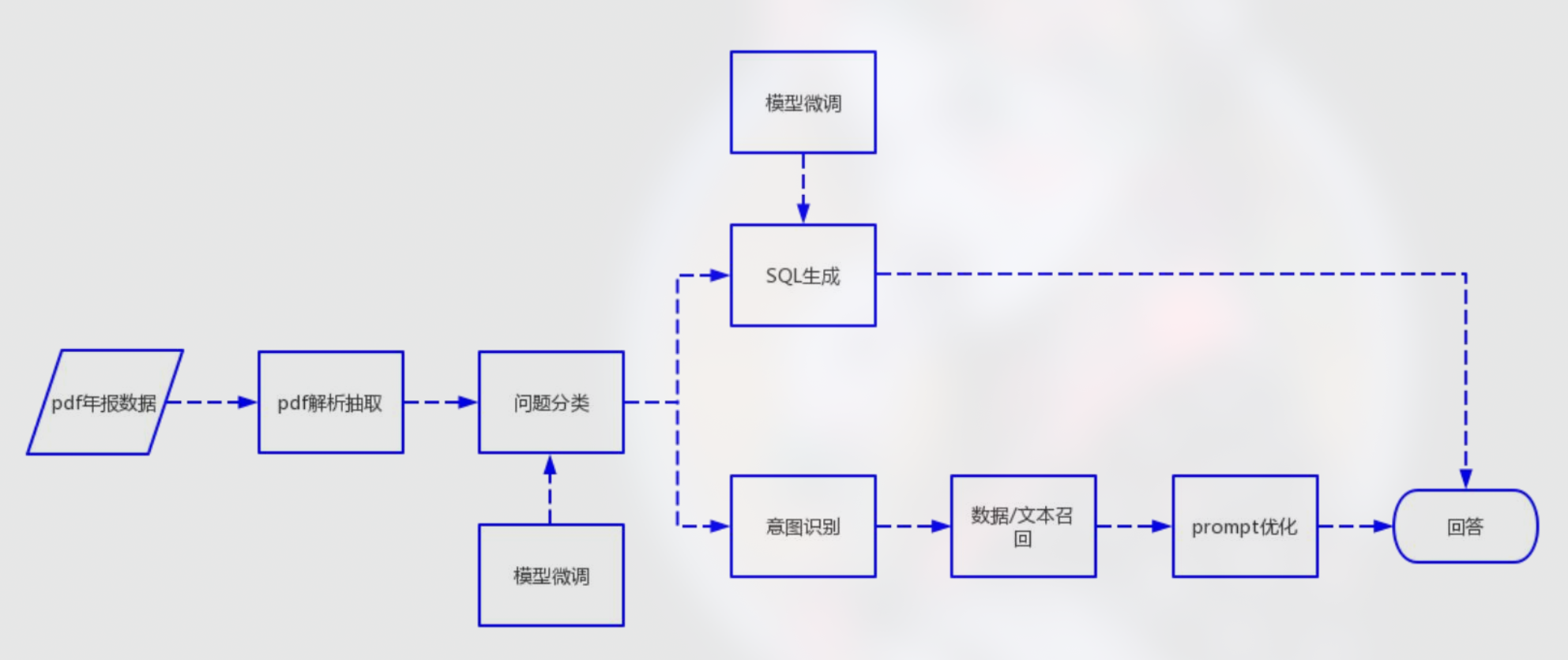
问题类型分类

馒头科技首先对问题进行 显式分类,将用户提问拆成几大类:
- 公司基本信息
- 公司员工信息
- 财务报表相关内容
- 计算题
- 统计题
- 开放性问题
这样做的好处是: 不同类型的问题可以走不同的处理路径,例如简单查数直接检索,计算题走拆分+公式链,开放题走检索增强生成。
Prompt 关键词提取
对用户原始问题,系统先从 Prompt 中提取 关键词,包括但不限于:
- 主体:公司名称/证券代码;
- 时间:年份、报告期;
- 主题字段:研发费用、财务费用、员工人数等;
- 操作类型:查询、对比、计算、分析等。
这一步既可以部分依赖 LLM,也可以结合规则对问题进行结构化表示,为后续检索与计算打下基础。

复杂计算题
对于“需要计算”的题目,馒头科技采用 “大问题拆成小问题”的问题链设计:
- 关键词匹配: 根据问题中的关键财务指标(如“毛利率、净利率、增长率”)匹配对应的 公式模版。
-
公式映射与问题链生成:
- 例如针对问题 研发费用增长率 \(\text{增长率} = \frac{\text{本期研发费用} - \text{上期研发费用}}{\text{上期研发费用}}\)
-
将公式拆成一组子问题:
- Q1:某公司 2021 年研发费用是多少?
- Q2:某公司 2020 年研发费用是多少?
- 逐子问题检索/求值: 对每个子问题单独检索对应年报片段、提取数值。
- 回填与计算: 将检索出的数值代入公式,完成计算。
- 生成最终答案: 把计算结果组合成自然语言回答,并视需要附带简单解释。
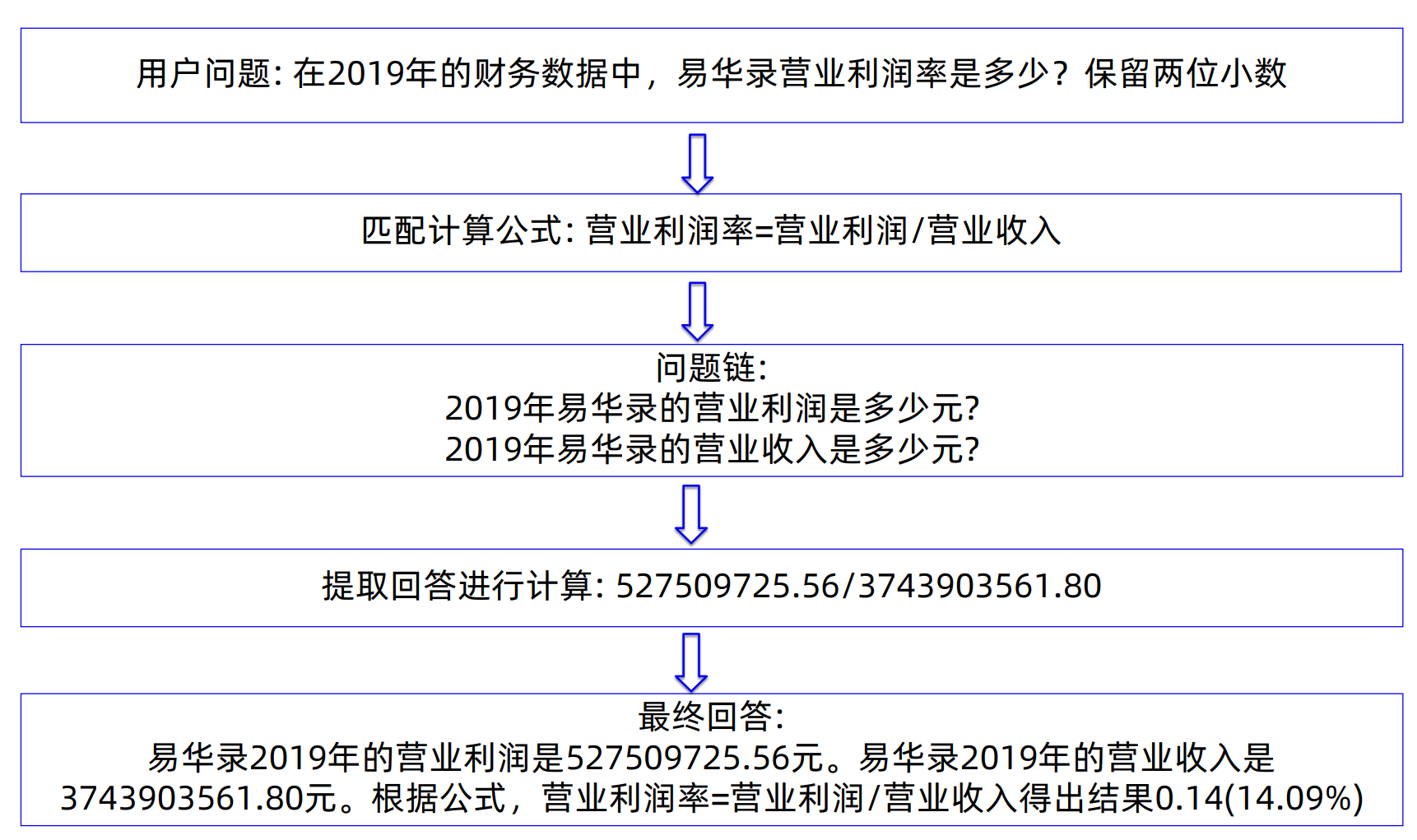
通过这种方式,复杂问题被转化为多个可控的“查数 + 公式计算”子任务,降低了对大模型“直接算对”的依赖。
方案二:吃辣子
“吃辣子”团队更强调对 问题结构要素 和 文档结构 的系统建模,从而提升对复杂题型的适配能力。
问题组成要素拆解
他们将问题拆成多个 语义要素,针对不同题型定义不同要素组合:
-
Type1:年报基础信息问答
要素:
主体(公司) + 年份 + 意图要素 -
Type1-统计题
要素:
地域 + 年份 + 意图要素 + 统计条件 -
Type2:计算题
要素:
年份 + 主体 + 意图要素 + 计算意图 -
Type3-1:结合财报的综合分析题
要素:
主体 + 年份 + 意图要素(非结构化数据) -
Type3-2:基础财务知识题
要素:
无主体 + 无年份 + 无特定年报要素(偏通识知识)
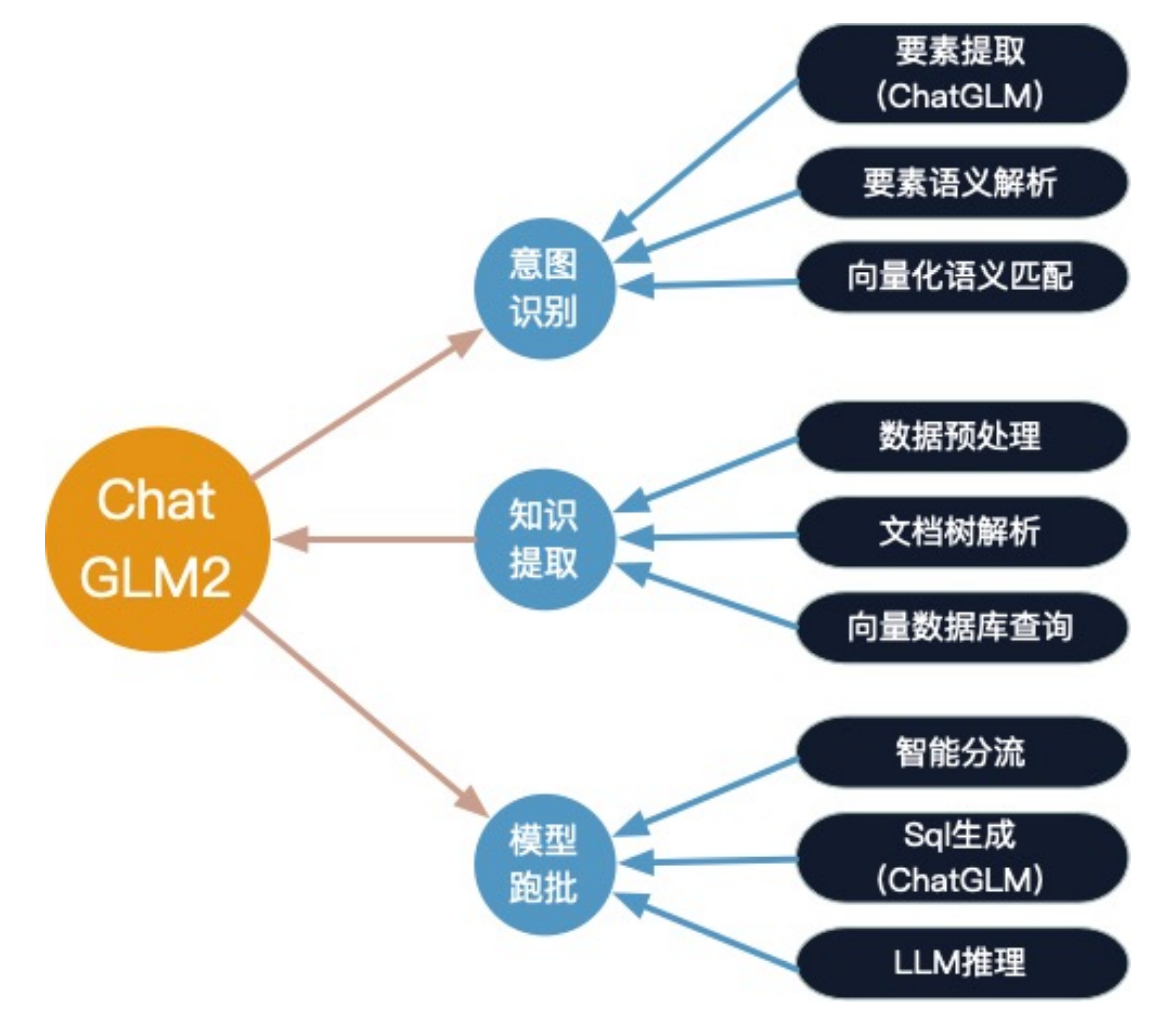
通过显式建模这些要素,系统可以:
- 精确锁定需要查找的文档/年份范围;
- 区分“从年报查数” vs “用金融常识回答”的问题;
- 为后续检索、召回和推理提供结构化信号。
文档处理与“文档树”
对于年报这样的长文档,“吃辣子”构建了 文档树(Document Tree) 的结构化表达:
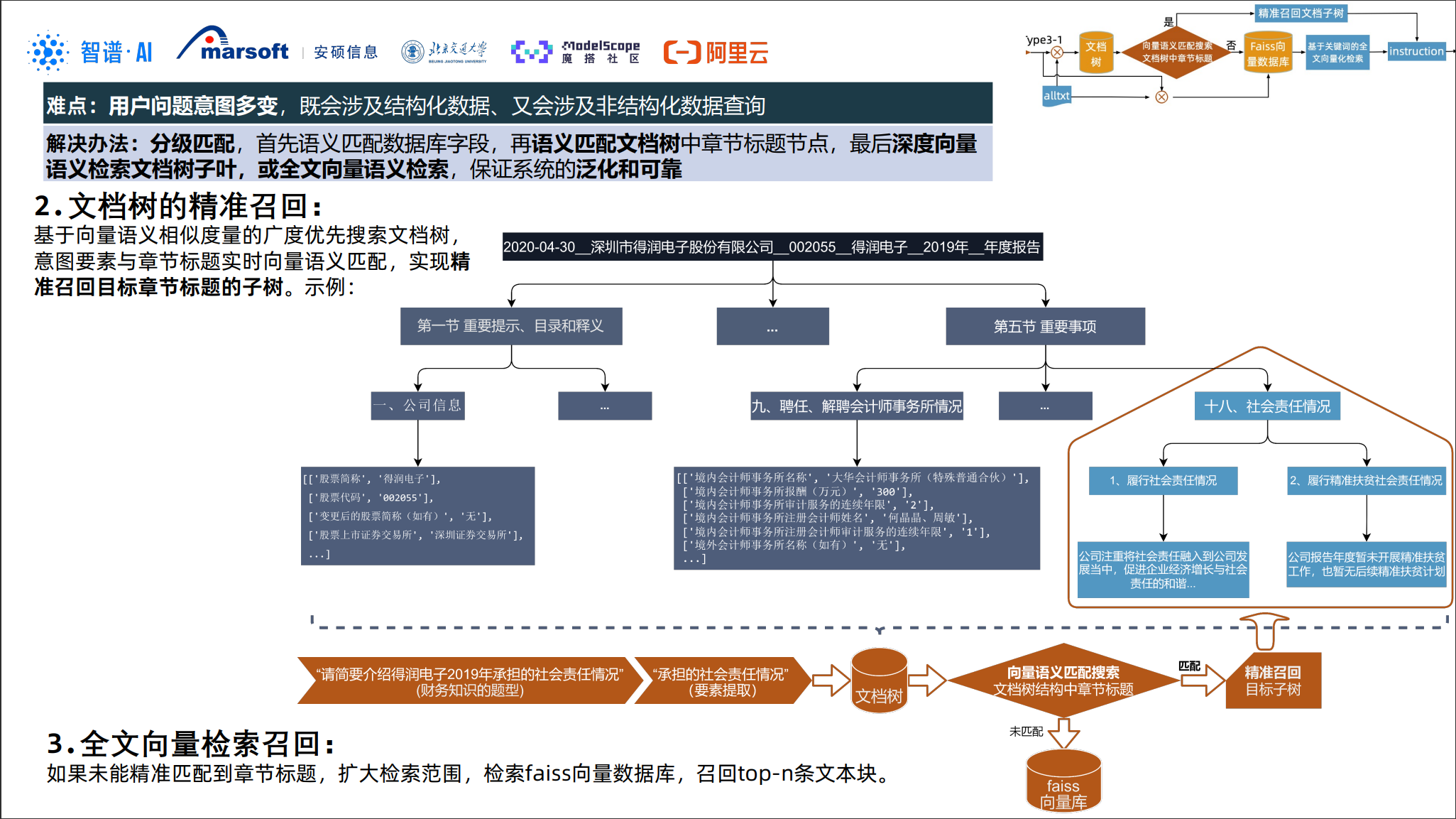
-
PDF 解析与章节划分:
按目录/标题层级切分:章节 → 小节 → 段落。
-
节点要素语义解析:
对每个节点提取其“要素标签”,例如:
- 适用主体(公司)
- 适用年份/报告期
- 涉及的财务指标(收入、成本、员工等)
-
表格处理:
将表格转为结构化数据,并与对应文本节点关联, 保留行列语义(科目名称、单位、期间等)。
处理流程与检索策略
基于上述结构,“吃辣子”的处理流程大致如下:
- 问题解析:识别题型与关键要素;
- 文档过滤:按主体/年份缩小文档范围;
-
要素级检索:
在“文档树 + 要素标签”上进行检索, 对于需要表格的题目,优先检索表格节点。
-
答案抽取与推理:
基础题直接抽取, 统计/计算题结合公式进行数据聚合与计算。
-
结果生成:
将数据/结论转换为自然语言答案。
同时,该方案强调 “基于关键词的全文向量化检索”: 在要素标签和关键词的约束下,再使用向量检索做细粒度召回,以兼顾精确度与召回率。
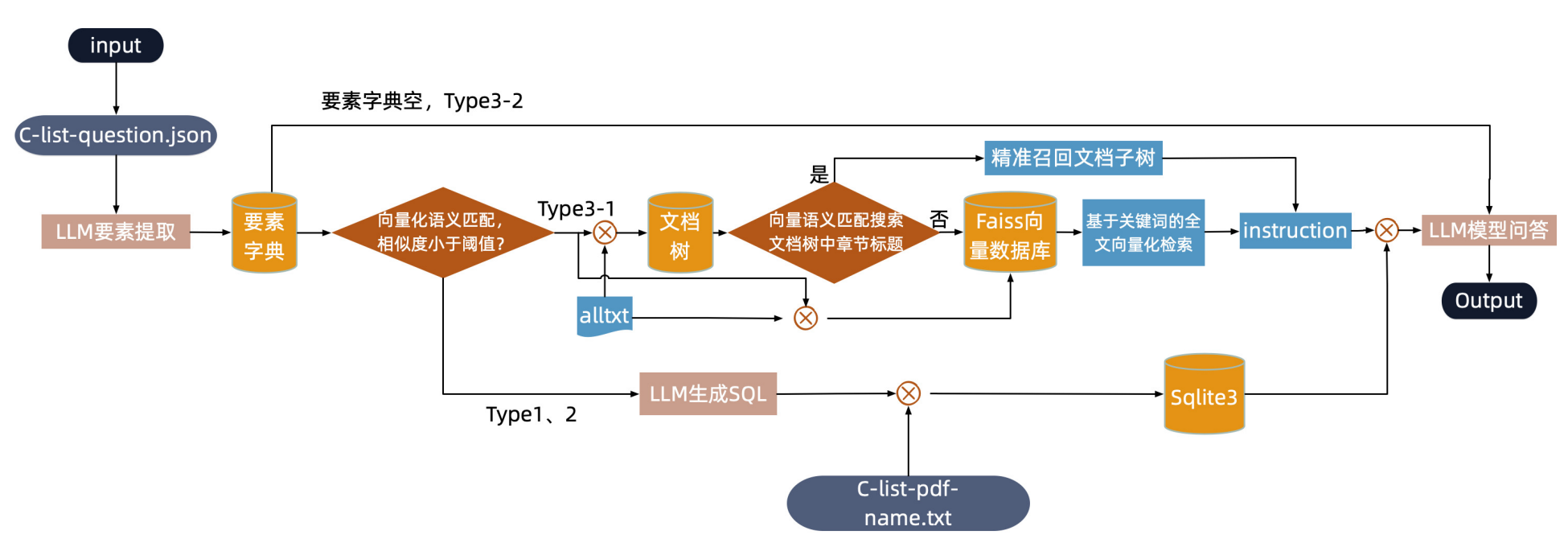
方案三:ChatGLM 反卷总
ChatGLM 反卷总是 FinGLM 中性价比非常高的一条路线:在不微调模型的前提下, 通过 正则 + 关键词抽取 + 表格转句子 的方式获得接近头部队伍的效果。
正则驱动的关键词抽取
在实践中,直接用原始 ChatGLM 做关键词抽取效果不稳定。 “反卷总”团队采用的做法是:
-
基于正则表达式抽取高置信关键词:
- 公司名、证券代码、年份;
- 金额(带“元”或单位)、百分比;
- 常见财务科目标识(“研发费用”“财务费用”“营业收入”等)。
-
结合 LLM 的多轮 history 提取:
不再用“单轮 Prompt 一步抽完”,而是通过构造 对话历史(history),逐步引导模型提炼关键词, 在每一轮中加入正则抽取结果作为“提示”,提升鲁棒性。

这种设计既利用了 LLM 的语义能力,又避免了完全依赖 LLM 所带来的不稳定性。
表格转句:让表格对大模型“友好”
年报中的大量关键信息存在于表格中,而原始表格对模型并不友好。 “反卷总”方案的关键之一,是将 表格转换成自然语言句子,例如:
“2021 年,A 公司研发费用为 1.23 亿元,同比增长 15.6%。”
步骤大致为:
-
解析表格行列:
- 行:科目名称
- 列:年份、金额、同比增幅等;
-
按行/列组合生成模板句子:
模板如:“在 {year} 年,{company} 的 {item} 为 {value},同比 {growth}。”
-
将这些句子作为“可检索文本”写入索引或向量库。
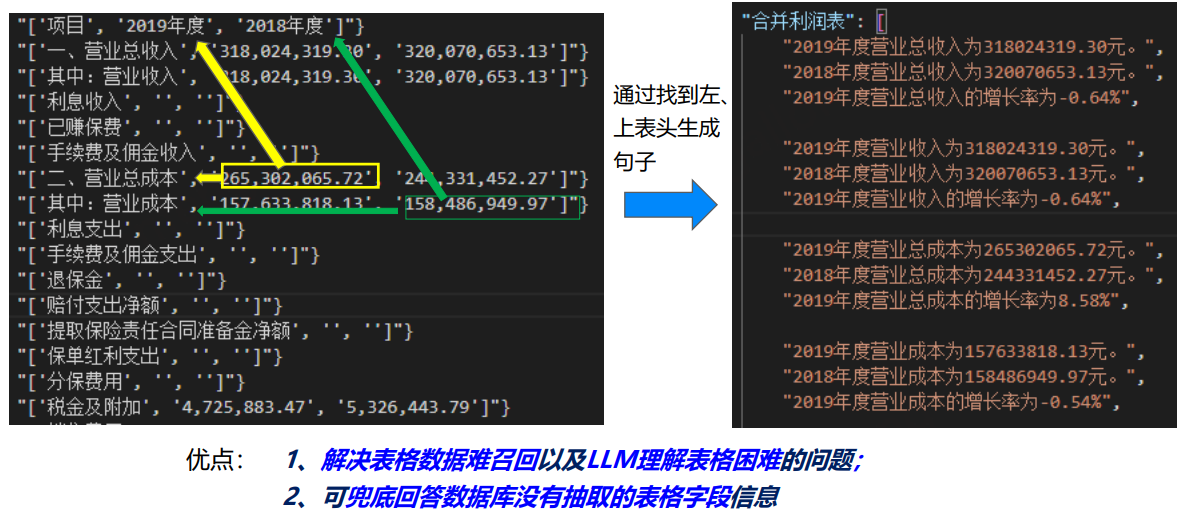
这样一来,LLM 在召回与阅读时就能“像读文本一样读表格”,大大缓解了复杂表格结构对模型的挑战。
核心技术要点对比与融合
综合以上三个方向,可以总结 FinGLM 技术路线中的几个关键共性和可复用经验:
问题侧
- 问题分类:区分基础查询、统计/计算题、开放分析题;
- 要素拆解:主体、年份、地域、指标、统计条件、计算意图等;
- 关键词抽取:正则 + LLM,多轮对话式 history 优于单轮 prompt。
这些手段本质上都是在“强行给自然语言问题加结构”,为后端检索与公式计算扫清障碍。
文档侧
- 文档树:章节/小节/段落的层级结构;
- 要素语义标注:节点绑定主体、年份、指标等标签;
- 表格语义化:表格转结构化数据,再转自然语言句子。
这样,年报不再只是一大坨文本,而是一个可检索、可推理的 金融知识图谱雏形。
检索与推理
-
检索层面:
关键词过滤文档范围, 在范围内做向量检索,找最相关片段;
-
推理层面:
对统计/计算题使用 公式模板 + 问题链拆解, 对开放题使用 多段证据 + LLM 归纳。
面向落地与复用的技术思路
从 FinGLM 的竞赛方案来看,一条较为通用且工程友好的技术路线可以是:
- 输入问题 → 问题分类 + 要素识别
- 关键词抽取(正则 + LLM history)
- 基于主体/年份/指标的文档过滤与检索(文档树 + 向量)
-
根据题型选择处理策略:
- 基础查询:抽取式问答;
- 统计/计算:公式驱动的问题链;
- 开放分析:多段证据 + LLM 生成;
-
答案生成与校验:
- 数值题做单位/数量级检查;
- 文本题重视逻辑连贯与引用依据。
通过以上路线,FinGLM 不仅给出了财报问答的一个竞赛解法,也为 通用 RAG 系统 提供了一套可借鉴的标准路径。