 lane4dev
lane4dev
Baidu KDD CUP 技术方案分析
Baidu KDD Cup 2022 的这个比赛,全名叫 Spatial Dynamic Wind Power Forecasting Challenge。组织方提供了一个叫 SDWPF 的数据集:
- 单一风场,134 台风机;
- 来自 SCADA 系统的历史数据,跨度大约半年,10 分钟一个点;
- 不只是功率和风速,还有温度、风向、叶轮状态、机舱状态等一堆内部状态;
- 每台风机还给了 平面坐标,可以构建空间关系。
比赛任务很明确: 给定每台风机最多 14 天 的历史数据,在没有未来气象预报的前提下,预测未来 48 小时(288 个时间点)的有功功率。
评价指标是 MAE 和 RMSE 的平均值,所有 134 台机组分别算分再平均。 从主办方后来发表的数据集论文来看,这个赛题的目的是为了「看一看当前长周期风功率预测方法的极限」。
为什么专门看第 1 名 HIK 和第 2 名 trymore?
排行榜上,HIK 拿了第一名,trymore 拿了第二名,两组分数差到小数点后第三位,非常接近。
但是两组人的解题思路还是有挺大差异,我认为特别值得拿出来说一说:
-
HIK:
- 用的是一个结构比较完整的多模块组合: 多关系图 + 时空 GRU 网络 + 分区 LightGBM 树模型 + 数据驱动集成规则。
- 非常强调 风电业务认知 和 模型互补。
-
trymore:
- 思路极度克制,单层 BERT 当长序列预测器 + 一个强业务化的后处理(负责日周期修正);
- 明知有空间信息,但最后甚至把其他特征都砍掉,只留风速 + 风向。
所以这两家其实代表了两种很典型的路径:
- HIK 组:复杂系统工程 + 强业务规则 + 多模型集成
- trymore 组:简洁主干模型 + 扎实数据分析 + 粗暴但有效的业务后处理
站在我自己正在做的风/光场功率预测的角度,这两条路径都值得好好学习参考。
第一名 HIK 组方案分析
论文标题就把核心思路表达清楚了: Complementary Fusion of Deep Spatio-Temporal Network and Tree Model for Wind Power Forecasting。
他们眼中的难点
HIK 组认为这个问题主要面对两个挑战:
-
多关系时空依赖很复杂
现实中的风场里,风机之间的关系不只靠谁离谁近, 还有谁的风速变化模式长得像,远处机组也可能强相关。 传统 ST-GNN 通常只用一种图(欧氏距离),不足以表达这种多关系。
-
数据分布很“皮”,固定融合方式不靠谱
风电功率分布高度非平稳:风速段不同、限电、故障、切入切出…… 如果集成时用一个固定权重去融合模型,可能对某些工况好,对另一些工况翻车。
他们的解决方案
用一个深度时空网络专门啃「多关系 + 长序列趋势」, 再用一个树模型盯着短期局部模式, 最后 根据当前功率段 + 预测步长 动态决定谁说了算。
整体框架:FDSTT 四件套
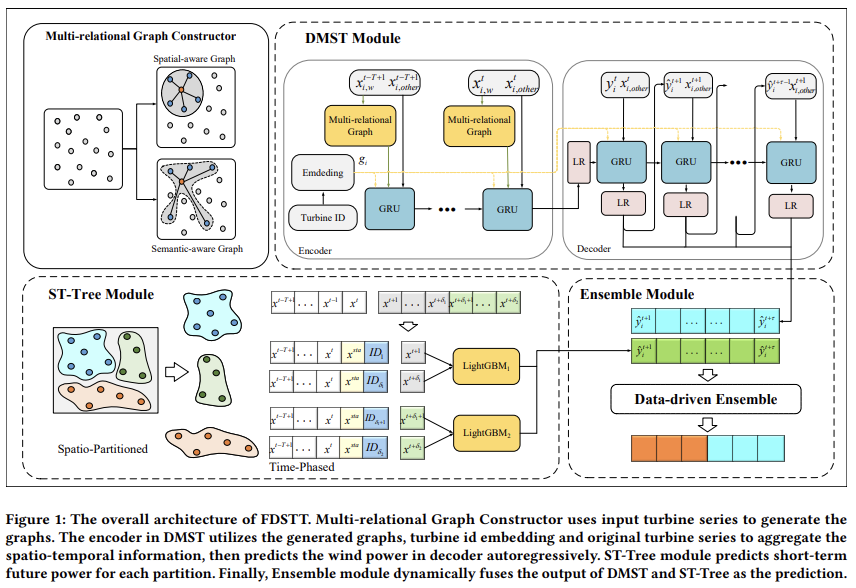
FDSTT 可以拆成四个模块:
- 多关系图构造器
- 深度多关系时空网络 DMST(Graph + GRU Seq2Seq)
- ST-Tree:空间划分 + 时间分段的 LightGBM
- 数据驱动的集成策略(if-else 规则)
从工程视角看,这其实是一套很标准的「多专家系统」: 每个模块专注处理某类 pattern,最后用一个简单但有业务含义的策略把它们粘在一起,这是一套非常工整的解决方案。
多关系图 + DMST
图怎么建?
-
空间图(spatial graph):
- 用风机坐标算欧氏距离,
- 选 top-K 最近邻做边,表达「物理邻居/尾流/局部地形」。
-
语义图(semantic graph):
- 基于风速的「差分相似度」,
- 谁的风速变化模式类似,就连谁——表达「远距离但同风带/同气候条件的机组」。
一个重要细节:
在图上做信息聚合时,只在图里传递 风速,而不是所有特征。
这点非常业务化:功率最核心的驱动因子就是风速,其它东西(温度、机舱状态等)更多是修正。
时序怎么建?
把「图聚合后的风速」 + 机组 ID embedding + 温度、风向、内部状态等特征拼在一起, 丢进一个 GRU Seq2Seq:
编码器吃过去 ~3 天(T≈432 个时间步), 解码器自回归地吐未来 48 小时(288 个时间步)的功率。
简单总结一下 DMST 做的事:
用多关系图把「每一台机组的风速」装上它的空间上下文, 再交给 GRU 去啃「长时序依赖」。
ST-Tree
考虑到深度网络擅长 长趋势 + 时空相关性,但对噪声和极端工况可能不够稳。 他们专门弄了一个 ST-Tree(Spatio-Partitioned Time-Phased Tree)来补短板。
关键点:
-
按风速相关性聚类,把风场切片
用风速 Pearson 相关系数,把 134 台机组分成若干子区域, 每个区域看成局部小风场,里面的机组共享一套树模型。
-
时间分段建树,而不是一步一模型
不做 288 个独立模型,而是一段时间由一组树负责, 用未来时间步 ID 作为特征,让模型区分 t+1、t+10、t+50……
-
特征偏向「短期 + 统计量」
过去 ~30 个时间步的风速 + 功率, 过去 14 天的 max/min/mean/median, 当前时刻的环境 & 机组状态。
这部分完全是熟悉的树模型时间序列工程套路,但做了空间分区这个增强。
集成
他们没有再加一个复杂的元学习器,而是写了一个很像生产规则的 if-else 集成策略(论文里的 Algorithm 1):
粗略逻辑是:
-
看当前平均功率在不在某个阈值区间(Δ_low, Δ_up)内:
如果功率极低或极高(cut-in/cut-out、饱和区等), → 短期预测 完全相信 ST-Tree。
否则, → 短期预测用 DMST 和 ST-Tree 做平均。
-
对于更后面的步长(中长期), → 直接用 DMST,但加一个经验性的偏置 ϕ,修正它在高功率区的系统偏差。
本质上,这就是在用功率水平当作分类特征,切换不同的专家组合。
我的收获
从论文和消融实验的结论可以抽几条对自己有用的点:
-
多模型互补是真的有用
只用 DMST < 只用 ST-Tree < 组合起来, 深度 + 树各管一摊,是能跑出实实在在性能差异的。
-
“多关系图 + 只对关键特征做图卷积”是个好范式
不要啥都往图里扔, 先问一句:这个变量是不是决定性的? 是才拿它做图上的信息传播。
-
用业务变量当「集成开关」很香
他们用的是功率段, 放到自己项目里,可以是:风速区间、或者其他的气象/非气象数据。
-
风场可以先按风速/功率统计特征分区,再在每个区里做建模
- 对应到光伏/多场站场景,也可以按容量、地形、调度特性分区。
第二名 trymore 组方案分析
第二名的方案叫: trymore: Solution to Spatial Dynamic Wind Power Forecasting for KDD Cup 2022。
如果说 HIK 是 架构+模块都很完整的系统工程, 那 trymore 就是「把复杂东西试了一圈之后,收缩回一个极简核心」。
他们的总体策略:趋势交给 BERT,日周期交给后处理
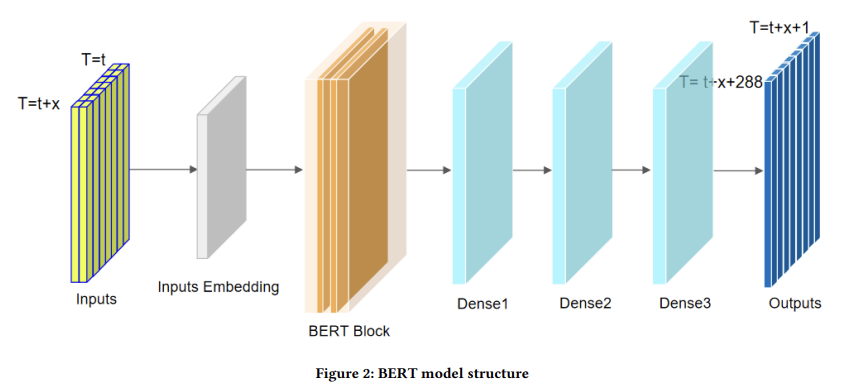
他们的路线可以一句话概括:
用一个结构尽量简单的 BERT做长序列预测, 然后用一个基于历史统计的日内周期模板,给预测曲线“补形状”。
对比 HIK:
- HIK:大量利用空间信息、多关系、树模型。
- trymore:最后干脆放弃复杂的空间建模,只做单机组时间序列,但补了一个非常业务化、非常粗暴的后处理。
数据处理:滑窗 + 把特征砍到只剩风速 / 风向
他们的数据处理非常工程师思维:
-
滑动窗口
历史最长 14 天,取定长 288 步的历史 → 288 步未来。 10 分钟一个步长,样本数量大幅增加。
-
缺失与异常值
uniform 策略:全部用前一个有效值填充,训练和推理保持一致。
-
归一化
输入特征做 Min-Max,[0,1], 目标功率保留原单位,便于后处理直接在物理量级上做算术。
-
特征选择(重要):
他们认真试了: 时间特征(小时、日)、 滞后/滚动统计、 温度、内部状态、空间坐标……
最终发现: 这些东西没有带来稳定收益,甚至导致过拟合, 最终 只保留风速 + 风向 两个输入,反而效果最好。
这一步对我来说是一个提醒:
不是“堆更多特征 = 更好”, 在长序列问题里,更干净、直指本质的特征会让模型更稳。
模型结构
他们的最终模型结构也很克制,只用了一个小而稳的单层 BERT:
- 输入:shape 大致是
[batch, 288, 2] -
编码器:
单层 Transformer encoder(BERT 风格):
- hidden size = 32;
- 1 个 attention head;
- 没有特别复杂的 position embedding trick。
-
输出:
3 层全连接 + dropout, 把时间 + 特征维的信息压成
[batch, 288]的未来功率序列。
训练设置也很日常:Adam、RMSE loss、batch=1024、训练 3 个 epoch 左右。
从复杂度看,这个模型在工业场景推理成本也很友好。
最关键的业务 trick
纯 BERT 模型预测出来的曲线,在数值上还可以,但日内形状不对:
历史数据里是「白天高、夜里低」很明显, 模型输出则更平滑,甚至有点「抹平日内周期」的倾向。
他们的做法非常简单粗暴,但效果极佳:
- 从历史数据中统计一个 平均日波形,可以理解为每 10 分钟一个点的典型日功率曲线;
- 对这个模板做标准化处理,再乘一个经验系数(比如 36,对大值再乘 1.1)放大;
- 根据预测起点对应的时间,把这条模板对齐,加到 BERT 的预测结果上。
这一步本质上是在说:
不管模型怎么瞎搞,物理规律不能丢, 该有的日内起伏,后处理给你强行加回去。
我的收获
整篇论文读下来,可以总结几点对我有用的认知:
-
在统一数据处理与验证方案下,BERT 比一票 RNN/TCN 更稳
尤其是在长序列(288 步)设置下, 注意这里的 BERT 是非常小的版本,而不是巨无霸。
-
空间信息、复杂特征有潜力,但实现难度不小
他们也试过 GCN-LSTM 等 ST 模型,本地分数很漂亮,但线上不稳定, 最后退回了纯时间序列解法,这说明 实现质量 在任何时候都是硬门槛。
-
业务后处理可以改变模型“气质”
不调整模型结构,只从业务视角给输出加一个日内模板, 对结果曲线的形状和指标都有显著提升。
宏观对比
把两组的思路摆在一起看,很像“解同一道题的两张标准答案”。
空间信息要用到什么程度?
-
HIK 组:
把空间信息用到极致:坐标 → 空间图;风速关联 → 语义图, 还基于风速相关性做区域划分,树模型按区域建。
-
trymore 组:
尝试过时空模型,但线上表现不稳定,最终干脆不用空间特征, 每台机组独立建模,只借助时间序列 + 日周期。
从结果上看,空间建模不是必须项,而是加分项: 有时间 & 人手,可以像 HIK 一样精心设计, 资源有限时,先把时间序列 + 业务后处理打磨好,也是一条能走通的路。
多模块系统 vs 单模型主干
-
HIK 组:
DMST(Graph+GRU) + ST-Tree(LightGBM) + Ensemble, 每个模块都不算极端复杂,但组合起来是标准的「系统工程」。
-
trymore 组:
主干只是一层 BERT + MLP, 真正的“工程感”更多体现在数据处理和后处理上。
做项目时要首先想好: 要不要一上来就搞多模型集成? 还是先把一个小而稳的主模型打磨好,再考虑加 tree / graph 这些东西?
业务认知的注入方式
-
HIK 组:
把业务写进「结构」里:图怎么建、区域怎么划、深度模型哪段时间负责、树模型哪段时间负责、用功率段做集成开关。
-
trymore 组:
把业务写进「后处理」里:用平均日波形修正模型输出的形状。
两种方式都很值得我以后组合使用: 架构设计时尽量「结构上体现业务认知」, 但不要忘了,后处理是最后一道 “业务兜底线”。
写在最后
这一段我不纠结技术细节,而是专门给自己写一点“方法论”的东西。
做加法 vs 做减法
在面对特征的选择上,两组人有一个特别直观的对比:
-
HIK 组:
特征工程偏「加法」+ 结构化: 图里只用风速, 时序里用环境、内部状态、时间信息等一整套, 树模型这边又做了大量统计特征、区域特征。
-
trymore 组:
特征工程偏「减法」: 测了很多(温度、时间特征、滚动统计、空间信息等等), 最终只保留 风速 + 风向 两个特征,其他都被证明“帮不上忙”。
这对我自己的提醒是: 特征工程不只是“多做一点”,也包括“敢砍掉没用的”。
方法论上可以抽象成几个层次:
-
先用业务直觉列候选,再用实验做“生死裁判”
先画一个脑图:这个业务里有哪些可能有用的信息通道? 然后用统一的数据处理 & 验证划分,一刀一刀把“没明显贡献甚至反向”的特征砍掉。
-
对不同子模型,特征可以“专用”
HIK 就是: 图模块只对风速做聚合(强驱动力), 树模型则吞掉更多“杂信息 + 统计量”, 深度模型吃的是“风速上下文 +一部分状态特征”。
不用所有模块都吃一模一样的 feature,这本身就体现了对模型能力边界的理解。
-
明确“信息量 vs 复杂度”的 trade-off
trymore 少特征方案能胜出,很大程度是因为在长序列 + 大样本下,简单特征 +简单模型更稳。
模型理解 = 技术理解 × 业务理解
这两篇方案让我更确信一个事:
理解模型这句话,如果只停留在「这是个 GRU / BERT / LightGBM」,其实没什么用。 真正有用的,是把模型看成业务映射的一部分。
具体来说:
-
HIK 对模型的理解:谁擅长什么?
- Graph+GRU:擅长建模「多机组、多关系、长时间跨度」的平滑趋势,但在极端工况可能偏保守;
- LightGBM:擅长拟合「短期局部模式 + 噪声和非线性拐点」,但外推能力有限;
- 集成规则:用功率段这个业务量来决定“当前该听谁的”。
这其实是一种“能力分工表”:
模块 更擅长的业务场景 DMST 正常运行、风况连贯、需要看几天趋势的时候 ST-Tree 刚起风、要停机、限电、突发异常、短期跟踪 -
trymore 对模型的理解:让 BERT 只做“该做的那一段”
他们没有指望一个小 BERT 同时学会“趋势 + 日周期 + 限电形状”, 选择只让 BERT 负责长趋势,日周期由后处理来填,空间关系则暂时放弃。 这其实是用“职责边界”来约束模型,防止它在信息太杂时“啥都学一点,啥都不精”。
对我来说,这比记住任何一个公式都更有价值:
以后选模型时,先给每个候选模型写一个“它在这个业务里最适合解决哪一类子问题”的说明书, 再决定该怎么拆任务、怎么组合,而不是堆在一起看谁分数高。
用神经网络解决问题,不是“力大砖飞”
KDD Cup 这种比赛,很容易让人误解成一场「谁的算力更大、模型更复杂,谁赢」。 但这两支队伍的公开方案恰好说明了相反的东西:
HIK 的 FDSTT 虽然模块多,但每块都不算巨大网络,更像是精心设计的多组件系统, trymore 则直接告诉你:单层 BERT + 精细验证 + 强后处理,就能拿到前列。
在我看来, 所谓“工程上的系统与效率”,可以粗暴分成三层:
- 问题拆解对不对?
- 验证与评估做得扎不扎实?
- 模型 & 特征的复杂度是不是和问题匹配?
这次两个方案都在不约而同强调一些“非模型”的东西: 例如 SDWPF 数据集论文本身也反复强调这个任务的难点在于长周期 + 空间动态 + 非平稳,需要在方法上做系统设计,而不是单纯换一个更大的神经网络。
对领域知识的理解,不是“加几列特征”那么简单
最后一个收获,其实是整个笔记里最想留给自己的: 所谓“懂业务”,不是简单地在表上多加几列字段,而是敢用业务知识去“删东西”和“定规则”。
在这两篇方案身上,我能看到几种不同层面的“领域理解”:
-
敢放弃一些理论上“应该有用”的信息
trymore 在实验里发现:温度、时间特征、滞后统计、空间坐标加进去,带来的不是稳定提升,而是复杂度和不确定性,于是干脆删掉。 这背后其实是一种“对业务信噪比结构的判断”:在这个时间尺度和任务上,风速/风向几乎占了绝大部分可用信号,其他变量的噪声反而更大。
-
敢把业务经验写成硬规则
HIK 用功率段来切换集成策略, trymore 用平均日功率曲线来修正预测形状。 这都是典型的“工程 vs 纯模型”的分界:你愿不愿意承认有些东西用规则比用网络更合适。
-
敢承认现阶段做不到“业务全部 end-to-end”,然后拆问题
HIK 承认一套模型搞不定所有跨度的时空依赖,于是拆成:图 + 深度时序 + 树 + 集成, trymore 承认一个小 BERT 学不好日周期,于是把日周期交给后处理。
这些设计背后,其实反映的是同一件事: 领域知识不只是“附属信息”,而是你设计系统边界、划分模块的依据。
对我以后做风电/光伏这类复杂项目时,是一个非常重要的提醒: 先把“我对这个系统的理解”写成几个清晰的假设,再去选模型、画架构,而不是反过来。
如果以后你再回来看这篇笔记,我希望自己记住这一句话: 好的模型方案,看上去像是在做“算法”,本质上是在做“如何利用业务认知的系统工程”。