 lane4dev
lane4dev
使用 Darts 对风电功率进行时间序列预测:从 Transformer 到 TFT
本文通过一个真实的风电功率数据集,演示如何使用 Darts 这个时间序列库完成从数据准备、建模到可视化预测区间的完整流程。 我们会依次用到两个模型:
- 基于
Transformer的序列到序列模型 - 更强大的
Temporal Fusion Transformer (TFT),带协变量与分位数预测
数据集为:
Bangaluru_Wind Generation 2017–2021
记录了 2017–2021 年间某风电场按时间的发电功率(kW)。
环境与依赖
首先导入本次会用到的基础库和 Darts 相关组件:
import warnings
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.CRITICAL)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.dataprocessing.transformers import Scaler
from darts.models import TFTModel, TransformerModel
from darts.utils.statistics import check_seasonality, plot_acf
from darts.utils.timeseries_generation import datetime_attribute_timeseries
from darts.utils.likelihood_models import QuantileRegression
这里需要注意:
TimeSeries是 Darts 的核心数据结构,几乎所有模型都围绕它展开。Scaler用于对时间序列做标准化处理。TransformerModel/TFTModel是本文的主角。QuantileRegression用于支持分位数预测(预测区间)。
数据读取与预处理
读取 CSV 并设置时间索引
df = pd.read_csv(
"assets/Bangaluru_Wind Generation 2017-2021.csv",
header=0,
parse_dates=["Timeseries"],
)
df.drop("id", axis=1, inplace=True)
df.index = df["Timeseries"]
这里做了几件事:
- 使用
parse_dates直接把"Timeseries"列解析为datetime。 - 删除无用的
id列。 - 把
"Timeseries"设为 DataFrame 的索引,后续按时间重采样会更方便。
可以简单看一下基本统计信息:
df.describe()
| T amb (Degree) | Pressure mBar | Wind Speed at 76.8 m\n(m/sec) | WindDir (Degree) | DewPoint(Degree) | Relative Humidity(%) | Power Generated(kw) | |
|---|---|---|---|---|---|---|---|
| count | 39720.000000 | 39720.000000 | 39720.000000 | 39720.000000 | 39720.000000 | 39720.000000 | 39720.000000 |
| mean | 25.572173 | 934.686367 | 6.835899 | 187.125025 | 16.313995 | 61.426873 | 411.266486 |
| std | 4.192134 | 3.164395 | 3.772081 | 94.581335 | 4.833753 | 22.058792 | 500.147584 |
| min | 14.500000 | 923.500000 | 0.000000 | 0.000000 | -5.000000 | 8.500000 | 0.000000 |
| 25% | 22.400000 | 932.500000 | 3.920000 | 90.000000 | 13.300000 | 43.900000 | 0.000000 |
| 50% | 24.900000 | 934.700000 | 6.040000 | 238.000000 | 18.100000 | 64.000000 | 179.885000 |
| 75% | 28.200000 | 936.900000 | 9.150000 | 268.000000 | 20.000000 | 80.600000 | 615.755000 |
| max | 39.100000 | 944.900000 | 25.480000 | 360.000000 | 23.900000 | 99.300000 | 1500.000000 |
重采样为小时数据
原始数据的时间间隔可能并不规则,我们统一重采样为按小时时间序列:
df = df.resample("H", convention="start").sum()
resample("H"):以小时为频率重采样;sum():如果某小时内有多条记录,就累加功率值。
转换为 Darts TimeSeries 并可视化
构建 TimeSeries
df_ts = TimeSeries.from_dataframe(
df,
value_cols="Power Generated(kw)",
fill_missing_dates=True,
freq="H",
)
关键参数说明:
value_cols:指定要作为时间序列值的列(这里是发电功率)。fill_missing_dates=True:自动补全缺失时间戳。freq="H":告诉 Darts 我们的数据是按小时的。
简单可视化
plt.figure(figsize=(21, 9))
df_ts.plot()
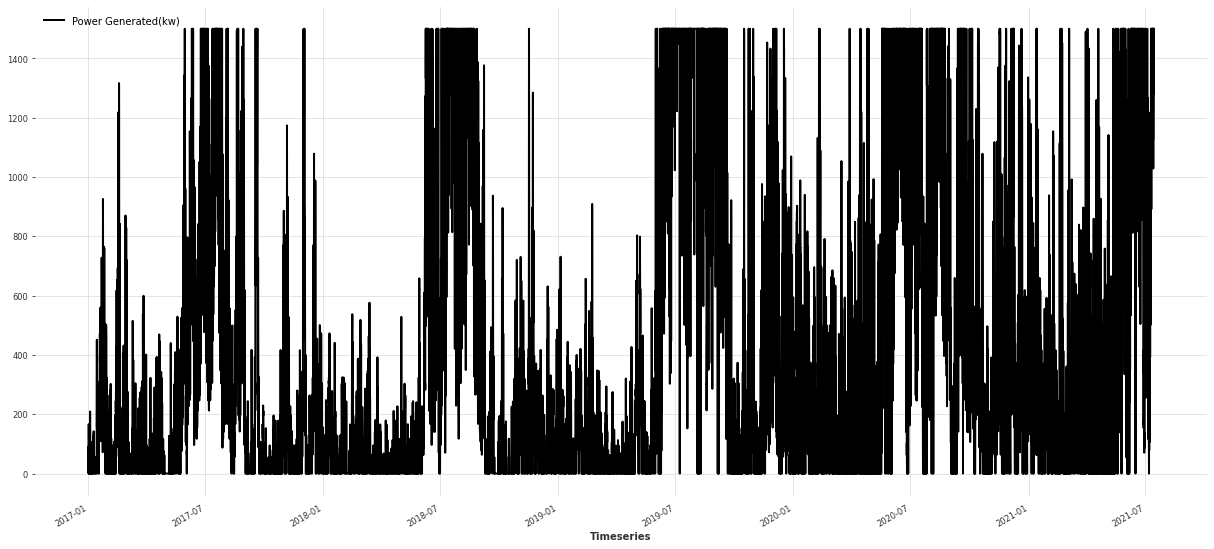
从这张图里,你大概可以看出:
- 整体发电功率随季节、天气震荡;
- 不同时段的波动幅度和趋势存在差异。
这些特征也会影响后续模型的选择和效果。
划分训练集与验证集
我们用 2017–2020 的数据训练模型,2021 年的数据验证模型。
代码里选用的边界是 2021-01-01:
train, val = df_ts.split_before(pd.Timestamp("20210101"))
len(train), len(val)
可视化一下划分后的序列:
plt.figure(figsize=(21, 9))
train[-168:].plot() # 训练集最后一周
val[:72].plot() # 验证集前 72 小时
plt.legend(["train (last 7 days)", "val (first 3 days)"])
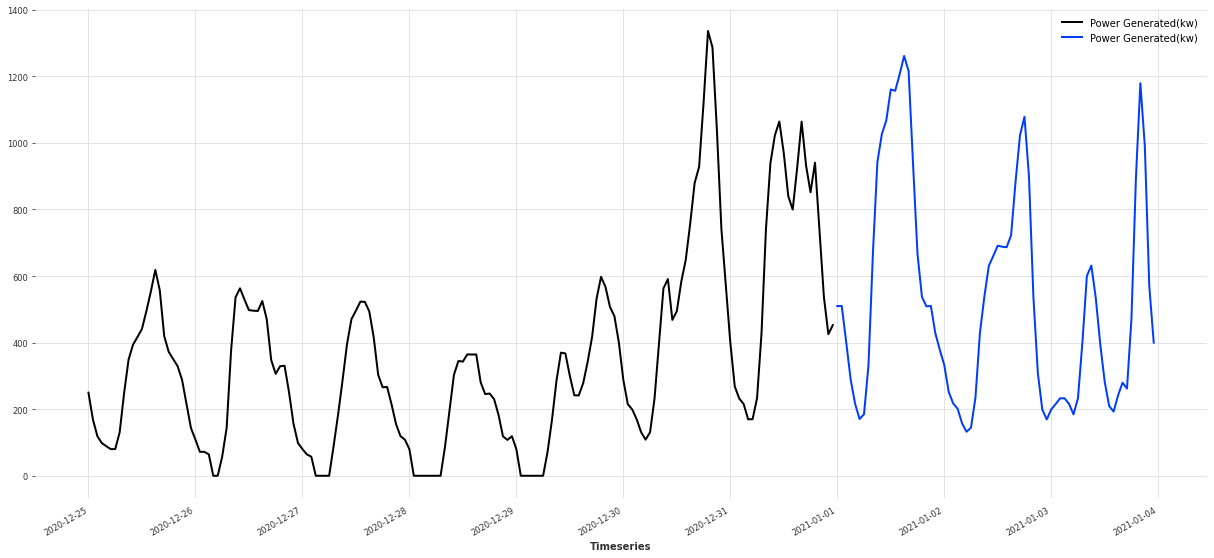
这样可以直观地看到模型要接力预测的那一段区域。
标准化:用 Scaler 处理时间序列
深度学习模型对数值尺度通常比较敏感,所以在 Darts 里较常见的一步是对序列做缩放或标准化。
# 注意:只在 train 上拟合变换,避免信息泄露
transformer = Scaler()
train_transformed = transformer.fit_transform(train)
val_transformed = transformer.transform(val)
series_transformed = transformer.transform(df_ts)
fit_transform(train):只用训练集来学习缩放参数(例如均值和标准差)。- 对
val和完整序列df_ts使用同一个transformer做transform,保证它们处在统一尺度上。
使用 TransformerModel 做时间序列预测
模型配置
TransformerModel 是基于序列到序列的 Transformer 架构,非常适合处理较长的时间依赖。
my_tf_model = TransformerModel(
batch_size=32,
input_chunk_length=168,
output_chunk_length=36,
n_epochs=40,
model_name="power_transformer",
nr_epochs_val_period=5,
d_model=16,
nhead=4,
num_encoder_layers=2,
num_decoder_layers=2,
dim_feedforward=168,
dropout=0.1,
random_state=42,
optimizer_kwargs={"lr": 1e-3},
save_checkpoints=True,
force_reset=True,
)
几个关键参数的含义:
input_chunk_length=168:每次输入过去 168 个时间步(7 天的小时数据)。output_chunk_length=36:模型一次预测 36 个时间步(36 小时)。n_epochs=40:训练轮数。d_model, nhead, num_encoder_layers, num_decoder_layers:和 Transformer 的结构相关,控制模型容量。save_checkpoints=True:保存最佳权重,方便之后加载或恢复。
模型训练
my_tf_model.fit(
series=train_transformed,
val_series=val_transformed,
verbose=True,
)
训练过程中,Darts 会自动:
- 按指定的
input_chunk_length/output_chunk_length滑动窗口喂数据; - 用
val_series做早停和监控。
训练完成后,可以把模型存盘:
my_tf_model.save_model("transformer_v010.pth.tar")
使用 Transformer 做短期预测
以预测未来 48 小时为例:
pred_series = my_tf_model.predict(n=48)
可视化预测结果与真实值:
plt.figure(figsize=(21, 9))
# 取预测前的一段历史 + 预测区域
series_transformed[35064-168 : 35064+72].plot(label="actual")
pred_series.plot(label="our transformer")
plt.legend()
这里 35064 是 notebook 中选取的一个时间索引,用来聚焦某个具体时间段的预测效果。
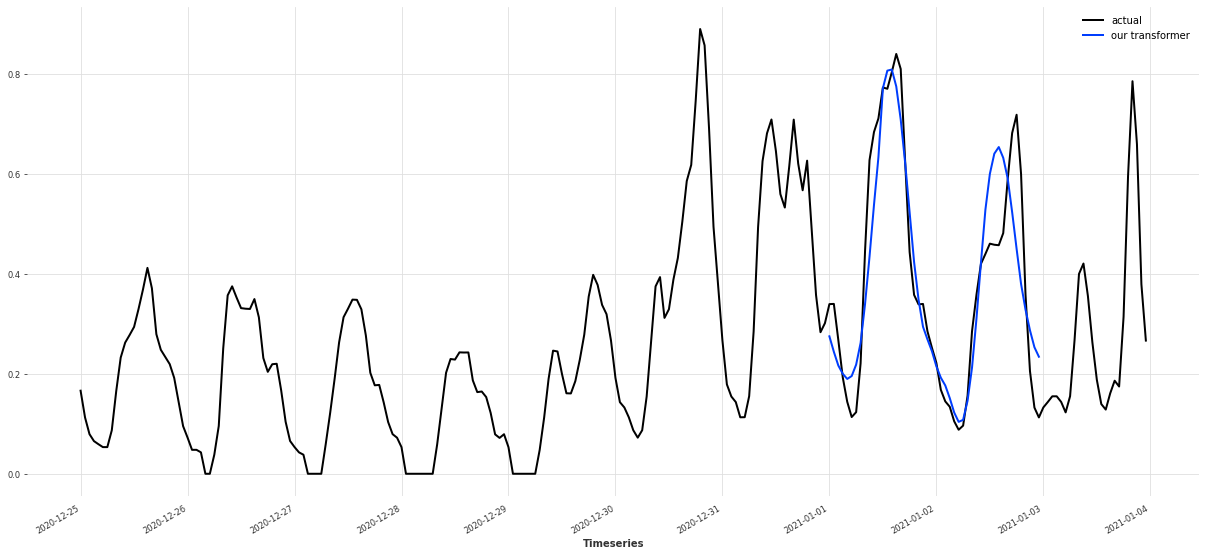
通过这张图,你可以观察:
- 模型是否捕捉到了功率变化的趋势;
- 预测是否明显偏高或偏低。
构造协变量:为 TFT 做准备
与 Transformer 模型相比 TFT (Temporal Fusion Transformer) 的一个重要特点是可以显式使用 协变量(covariates),
即那些与目标变量相关但非直接预测目标的时间序列特征,比如「年份、月份、线性时间索引」等。
构建时间特征协变量
# 创建 year 和 month 特征
covariates = datetime_attribute_timeseries(
df_ts, attribute="year", one_hot=False
)
covariates = covariates.stack(
datetime_attribute_timeseries(df_ts, attribute="month", one_hot=False)
)
# 创建一个线性递增索引特征
covariates = covariates.stack(
TimeSeries.from_times_and_values(
times=df_ts.time_index,
values=np.arange(len(df_ts)),
columns=["linear_increase"],
)
)
covariates = covariates.astype(np.float32)
在这一步里,我们得到了一个多变量时间序列,包含:
year:年份month:月份linear_increase:简单的线性自增索引(可以帮助模型学习长期趋势)
对协变量进行缩放
# 只在 train 时间段内拟合 covariates 的缩放器
scaler_covs = Scaler()
cov_train, cov_val = covariates.split_after(pd.Timestamp("20210101"))
scaler_covs.fit(cov_train)
covariates_transformed = scaler_covs.transform(covariates)
和前面目标时间序列一样,我们只用训练时间段的数据拟合缩放器,然后对完整协变量序列做变换。
使用 Temporal Fusion Transformer (TFT) 做分位数预测
定义分位数与模型
首先定义一组我们关心的分位数(预测区间所需):
# default quantiles for QuantileRegression
quantiles = [
0.01, 0.05, 0.1, 0.15, 0.2,
0.25, 0.3, 0.4, 0.5, 0.6,
0.7, 0.75, 0.8, 0.85, 0.9,
0.95, 0.99,
]
input_chunk_length = 168
forecast_horizon = 48
接着构建 TFTModel:
my_model = TFTModel(
input_chunk_length=input_chunk_length,
output_chunk_length=forecast_horizon,
hidden_size=64,
lstm_layers=2,
num_attention_heads=4,
dropout=0.2,
batch_size=32,
n_epochs=40,
add_relative_index=False,
add_encoders=None,
likelihood=QuantileRegression(quantiles=quantiles),
# loss_fn=MSELoss(), # 默认可以不用显式指定
random_state=42,
)
核心参数说明:
input_chunk_length=168:同样看 7 天历史。output_chunk_length=48:一次预测 48 小时。hidden_size, lstm_layers, num_attention_heads:控制网络容量。likelihood=QuantileRegression(...):启用分位数回归,让模型直接输出各个分位数的预测结果。
训练 TFT 模型
my_model.fit(
train_transformed,
future_covariates=covariates_transformed,
verbose=True,
)
my_model.save_model("tft_v020.pth.tar")
这里的重点是 future_covariates:
- 我们把「年、月、线性索引」这些协变量整个序列都传给模型;
- TFT 在训练和预测时都会利用这些信息来优化预测。
使用 TFT 做多分位数预测
预测未来 48 小时,并使用多个样本估计预测分布:
pred_series = my_model.predict(48, num_samples=168)
此时的 pred_series 不是单一曲线,而是带有不同分位数的 概率预测结果。
我们可以画出不同置信区间的预测带:
lowest_q, low_q, high_q, highest_q = 0.01, 0.1, 0.9, 0.99
label_q_outer = f"{int(lowest_q * 100)}-{int(highest_q * 100)}th percentiles"
label_q_inner = f"{int(low_q * 100)}-{int(high_q * 100)}th percentiles"
plt.figure(figsize=(21, 9))
series_transformed[35064-168 : 35064+72].plot(label="actual")
# 外层:1% ~ 99% 置信区间
pred_series.plot(
low_quantile=lowest_q,
high_quantile=highest_q,
label=label_q_outer,
)
# 内层:10% ~ 90% 置信区间
pred_series.plot(
low_quantile=low_q,
high_quantile=high_q,
label=label_q_inner,
)
plt.legend()
这张图非常有实用价值:
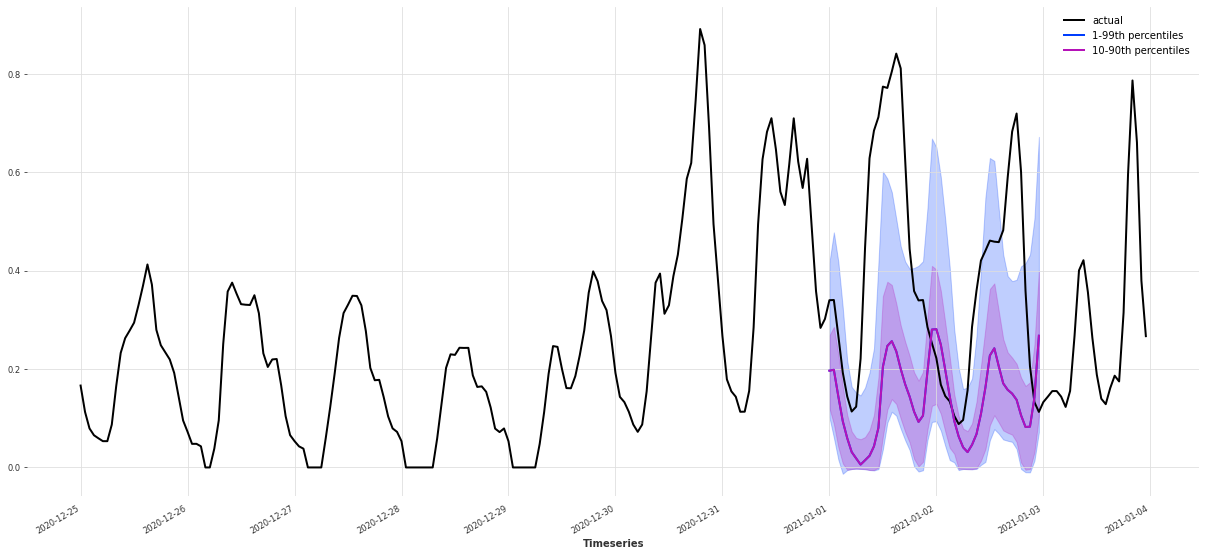
- 实线:真实的风电功率;
- 浅色带:较宽的预测区间(1%–99%),表示极端情况下的预测范围;
- 深色带:较窄的预测区间(10%–90%),表示模型认为更「典型」的预测范围。
通过对比真实值与预测区间的位置,可以直观判断模型的 不确定性建模能力 和 风险覆盖情况。
小结
通过这个风电功率预测的例子,我们基本走了一遍使用 Darts 进行时间序列建模的完整流程:
-
数据准备
- 读取 CSV、解析时间列;
- 重采样为规则时间间隔(小时);
- 用
TimeSeries.from_dataframe构建统一格式的时间序列。
-
划分训练 / 验证集
- 按时间点切分,不打乱顺序;
- 通过可视化确认切分是否合理。
-
标准化 / 预处理
- 使用
Scaler在训练集上拟合,再应用到验证集和全局数据; - 为深度学习模型提供更稳定的数值范围。
- 使用
-
使用 TransformerModel 做基线预测
- 设置输入 / 输出窗口长度;
- 训练模型,保存权重;
- 预测未来一段时间并可视化。
-
构造协变量 + 使用 TFTModel
- 构造时间特征(年、月、线性索引等)作为协变量;
- 对协变量同样进行缩放;
- 使用
TFTModel结合协变量进行预测; - 利用
QuantileRegression输出预测区间,并绘制不同置信区间带。